Hive性能调优实践
Hive基本介绍
架构
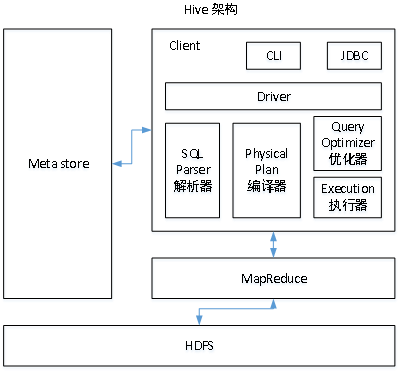
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;默认存储在自带的derby数据库中,也可以使用MySQL/PG存储Metastore。
Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
优点
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
避免了去写MapReduce,减少开发人员的学习成本。
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
Hive的HQL表达能力有限
迭代式算法无法表达
数据挖掘方面不擅长
Hive的效率比较低
- Hive自动生成的MapReduce作业,通常情况下不够智能化
- Hive调优比较困难,粒度较粗
Hive核心概念
排序
- Order By:全局排序,一个Reducer,ASC(ascend)升序(默认),DESC(descend) 降序;
- Sort By:每个Reducer内部进行排序,对全局结果集来说不是排序。
set mapreduce.job.reduces=3;; - Distribute By:类似MR中partition进行分区,结合sort by使用。注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前;
- Cluster By:当distribute by和sorts by字段相同时,可以使用cluster by方式。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
基本类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
复合类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | struct() |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() |
调优实践
Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
本地模式
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
1 | -- 设置自动选择Mapjoin |
Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
1 | -- 是否在Map端进行聚合,默认为True |
Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换。
数据倾斜
合理设置Map数
- 决定map数量的因素有哪些?
主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。
- 是不是map数越多越好?
如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
小文件合并
在map执行前合并小文件,减少map数:
CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式),HiveInputFormat没有对小文件合并功能。1
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
调整Map数
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
1
2
3// 调整maxSize最大值
// 让maxSize最大值低于blocksize就可以增加map的个数
computeSliteSize(Math.max(minSize, Math.min(maxSize, blocksize))) = blocksize = 128M1
2-- 设置最大切片值为100个字节
set mapreduce.input.fileinputformat.split.maxsize=100;调整Reduce数
1
2
3
4
5
6
7
8
9
10
11
12-- 方法一
-- 每个Reduce处理的数据量默认是256MB
set hive.exec.reducers.bytes.per.reducer=256000000
-- 每个任务最大的reduce数,默认为1009
set hive.exec.reducers.max=1009
-- 计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
-- 方法二
-- 在hadoop的mapred-default.xml文件中修改
-- 设置每个job的Reduce个数
set mapreduce.job.reduces = 15;过多的启动和初始化reduce也会消耗时间和资源。另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题。
并行执行
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。
1 | -- 打开任务并行执行 |
JVM重用
JVM重用是Hadoop调优参数的内容,其对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或task特别多的场景,这类场景大多数执行时间都很短。
Hadoop的默认配置通常是使用派生JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次。N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间,具体多少需要根据具体业务场景测试得出。
1 | <property> |
这个功能的缺点是,开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job中有某几个reduce task执行的时间要比其他Reduce task消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
推测执行
1 | <!-- mapred-site.xml --> |
扩展内容
样例
- union调优
1 | insert into table xx |
- 数据块大小
一个文件由2个数据块构成,在hdfs namenode不紧张的情况,多个不同节点上的map读取这个数据块,本地性较差,需要走网络拉取数据。相比于,一个文件由10个数据块构成,多个不同节点上map本地性较好,减少了网络传输,性能会有所提升。
- 数据格式
ORC对hive数据存储主流之一
- 表设计
1 | -- hive分区表 |
表的设计对于HiveSQL的性能有一定的影响,并不能说明分区分桶表性能一定比只分桶的表性能差,因为基于不同业务和上层的计算逻辑,表现出来的性能差异也会不同。
总结
Hive构建在大数据集群之上,包括了分布式计算、分布式存储和分布式调度等多个系统。因此,Hive的调优并不是单方面的调优,是一个涉及多个组件的系统化工程。
调优思路
分布式计算
学习大数据分布式计算的基本原理,比如MapReduce、Spark等。
分布式调度
学习使用YARN提供的日志,查看Job运行量化信息。
调优三部曲
改写SQL
grouping sets代替union、分解count(distinct)为count(group by)
比如,在小数据量下count(distinct)会优于count(group by),但大数据量数据发生倾斜时,count(group by)优于count(distinct),因为count(group by)会分为两个作业,第一阶段先处理一部分数据,缩小数据量。第二阶段在缩小的数据量上继续处理。在hive3.0中,开启hive.optimize.countdistinct,会自动调优count(disctinct)。
调优讲究适时调优,过早进行调优有可能做无用功,因此调优需要遵循一定的原则。如下:
理透需求原则,这是优化根本;
把握数据全链路原则,这是优化脉络;
1 | -- 查看元数据 |
没有瓶颈时谈论优化,这是自寻烦恼。
- 第一类问题:影响项目整体落地的问题、重大性能问题,在项目设计阶段就要规避。
- 第二类问题:不影响项目整体落地,但是影响部分功能,根据具体的业务要求进行调优,将优化放到有瓶颈点的地方去考虑和讨论。
SQL-hint使用
mapjoin、streamtable等hint使用
数据库配置调整
hive.vectorized.execution.enabled开启向量化、hive.exec.parallel、hive.exec.paralledl.thread.number
Hive规范
开发规范
- 单条SQL长度不宜超过一屏。
- SQL子查询嵌套不宜超过3层。
- 少用或者不用Hint,特别是在Hive2.0之后,增强HiveSQL对于成本优化(CBO)的支持,在业务环境变化时可能会导致Hive无法选用最优的执行计划。
- 避免SQL代码的复制、粘贴。如果有多处逻辑一致的代码,可以将执行结果存储在临时表中。
- 尽可能使用SQL自带党的高级命令做操作。比如多维统计中使用cube、grouping set和roll up等命令去替代多个SQL子句的union all。
- 使用set命令,进行配置属性的更改,要有注释。
- 代码里面不允许包含对表、分区、列的DDL语句,除了新增或删除分区。
- Hive SQL更加适合处理多条数据组合的数据集,不适合处理单条数据,且单条数据之间存在顺序依赖等逻辑关系。
- 保持一个查询语句所处理的表类型单一。比如,一个SQL语句中的表都是ORC或Parquet。
- 关注NULL值得数据处理。
- SQL表连接的条件列和查询的过滤列最好要有分区列和分桶列。
- 存在多层嵌套,内层嵌套表的过滤条件不要写到外层。
设计规范
- 表结构要有注释。
- 列等属性字段要有注释。
- 尽量不要使用索引。hive中处理批量处理大量数据,hive索引在表和分区有数据更新时不会自动维护,需要手动触发。索引在hive3.0之后被废弃,使用物化视图或数据存储采用ORC格式可以替代索引的功能。
- 创建内部表不允许指定数据存储路劲,由管理人员统一规划目录并固化在配置中。
- 创建非接口表,只允许使用ORC或Parquet。接口表指与其他系统进行的数据表,比如导入hive的临时表或者提供给其他系统使用的输出表。
- HIVE适合处理宽边(列数多的表),适当的冗余有助于Hive的处理性能。
- 表的文件块大小要与HDFS的数据块大小大致相等。
- 分区表和分桶表的适用。
命名规范
- 表以tb_开头;
- 临时表以tmp_开头;
- 视图以v_开头;
- 自定义函数以udf_开头;
- 原始数据所在的库以db_org_ 开头,明细数据所在库以db_detail_ 开头,数据仓库以db_dw_ 开头。
总结
优化基本流程:
- 选择性能评估以及各自目标,时延和吞吐量
- 系统由多个组件和服务构成,分组件和服务定义性能目标
- 明确当前环境下各个组件的性能
- 分析定位性能瓶颈:hive常见是磁盘和网络IO的瓶颈,其次是内存。涉及hive的执行计划、计算引擎基本原理。
- 优化产生性能瓶颈的程序或者系统:优化存储、执行过程和作业调度。
- 性能监控和告警:
- 在操作系统和硬件层面借助linux系统提供的工具,或者zabbix和ganglia开源工具。
- 软件层面,借助prometheus和grafana定制监控大数据组件。
- 作业层面,借助yarn timeline提供查看作业信息的监控。