OLAP引擎-Kylin基本介绍
基本介绍
Apache Kylin是Hadoop大数据平台上的一个开源MOLAP引擎。它采用多维立方体预计算技术,可以将大数据的SQL查询速度提升到亚秒级别。在2015年成为Apache的顶级项目,在2016年核心团队创立了Kyligence公司。
自Hadoop诞生以来,大数据的存储和批处理问题均得到了妥善解决,而如何高速地分析数据也就成为了下一个挑战。于是各式各样的“SQL on Hadoop”技术应运而生,其中以Hive为代表,Impala、Presto、Phoenix、Drill、Spark SQL等紧随其后。它们的主要技术是大规模并行处理(Massive Parallel Processing,MPP)和列式存储(Columnar Storage)。而预计算就是Kylin在大规模并行处理和列式存储之外,提供给大数据分析的第三个关键技术。
工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询,具体工作过程如下。
- 指定数据模型,定义维度和度量。
- 预计算Cube,计算所有Cuboid并保存为物化视图。
- 执行查询时,读取Cuboid,运算,产生查询结果。
架构演进
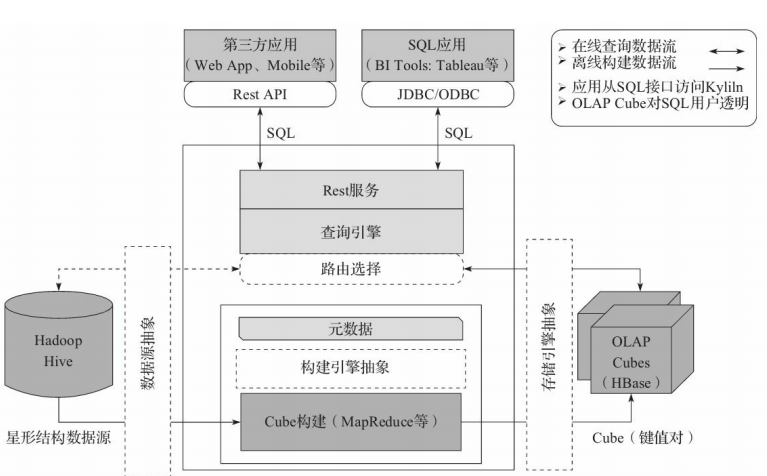
Kylin的三大依赖模块分别是数据源、构建引擎和存储引擎。比如,早期版本采用Hive接入数据源、MR离线构建cube,HBase存储cube,对外提供rest、jdbc接口来接收sql查询。Kylin为了更好地与时俱进,将这三部分进行了抽象,默认实现是Hive/MR/HBase。
当前,kylin经历了2.x、3.x到现在的4.0版本。支持了Kafka、第三方数据源接入,采用Spark进行Cube的构建,采用Parquet列式存储Cube,采用Spark SQL进行分布式查询。
kylin4的架构更适合上云,同时数据量越大性越好。但是针对那种简单的查询,是有一定的衰减,需要进行优化或者直接路由至查询服务,走本地spark的方式,避开spark on yarn的调度耗时。
主要概念
| 名词 | 解释 |
|---|---|
| 维度 | 观察数据的角度,比如时间、地区等 |
| 度量 | 统计值 |
| 事实表 | 事实表(Fact Table)指存储有事实记录(明细数据)的表,如系统日志、销售记录等;事实表的记录在不断地动态增长,数据量大。维度表(维表):保存了维度值,可以跟事实表做关联。常见的维度表如:日期表,地点表,分类表 |
| 维表 | 维度表(Dimension Table)或维表,有时也称查找表(Lookup Table), 是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。 常见的维度表有:日期表(存储与日期对应的周、月、季度等的属 性)、地点表(包含国家、省/州、城市等属性)等 优点:缩小了事实表的大小。便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。维度表可以为多个事实表重用,以减少重复工作。 |
| OLAP | OLAP(Online Analytical Process),联机分析处理,以多维度的方式分析数据,而且能够弹性地提供上卷(Roll-up)、下钻(Drill-down)、切片(Slicing、Dicing)和旋转(Pivot/Rotate)。 |
| BI | (Business Intelligence)即商务智能,指用现代数据仓库技术、在线分析技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。 |
| cubeid | 对于N个维度来说,组合的所有可能性共有2^N 种。对于每一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid. |
| cube | 即数据立方体,是一种常用于数据分析与索引的技术;它可以对原始数据建立多维度索引。通过Cube对数据进行分析, 可以大大加快数据的查询效率。 所有维度组合的Cuboid作为一个整体,被称为Cube。所以简单来说,一个Cube就是许多按维度聚合的物化视图的集合。 |
| Cube Segment | 是指针对源数据中的某一个片段,计算出来的Cube数据。通常数据仓库中的数据数量会随着时间的增长而增长,而Cube Segment也是按时间顺序来构建的。 |
| 星形模型 | 星形模型(Star Schema)中有一张事实表,以及零个或多个维度表;事实表与维度表通过主键外键相关联,维度表之间没有关联,就像很多星星围绕在一个 恒星周围,故取名为星形模型。 |
| 雪花模型 | 如果将星形模型中某些维度的表再做规范,抽取成更细的维度表, 然后让维度表之间也进行关联,那么这种模型称为雪花模型(Snowflake Schema)。 |
| 事实星座模型 | 星座模型是更复杂的模型,其中包含了多个事实表,而维度表是公用的,可以共享。 |
| cubeid剪枝优化 | Cube的剪枝优化则是一种试图减少 额外空间占用的方法,这种方法的前提是不会明显影响查询时间的缩减。在做剪枝优化的时候,需要选择跳过那些“多余”的Cuboid:有的 Cuboid因为查询样式的原因永远不会被查询到,因此显得多余;有的Cuboid的能力和其他Cuboid接近,因此显得多余。但是Cube管理员无法提前甄别每一个Cuboid是否多余,因此Kylin提供了一系列简单的工具来帮助他们完成Cube的剪枝优化。 以减少Cuboid数量为目的的Cuboid优化统称为Cuboid剪枝。主要方式衍生维度和聚合组。 |