Calcite处理和扩展流程解析
相关概述与特性,可以查看之前的文章《Calcite原理和经验总结》。
SQL处理流程
处理过程
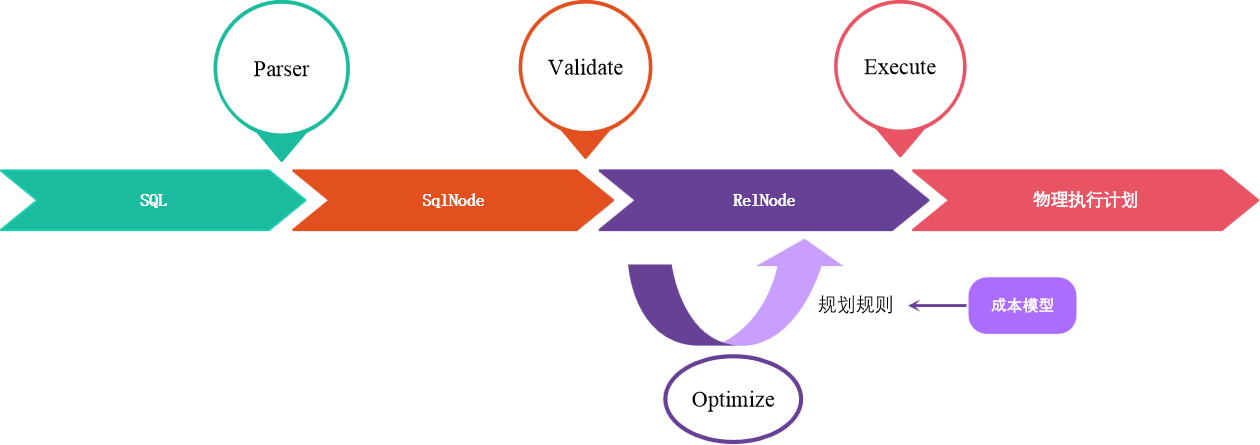
- Parser(SQL->SqlNode): 把 SQL 转换成为 AST (抽象语法树),Calcite 使用 JavaCC 做 SQL 解析.
- Validate(SqlNode->RelNode):
- 语法检查,根据数据库的元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树;
- 语义分析,根据 SqlNode 及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan)。
- Optimize(RelNode->RelNode): 逻辑计划优化,优化器的核心,根据前面生成的逻辑计划(relational expression,即关系代数)按照相应的规则(Rule)进行优化;
- Execute: 物理执行,生成物理计划,物理执行计划执行。
基础概念
| 类型 | 描述 | 特点 |
|---|---|---|
| SqlNode | SQL解析树 | Sql 经过解析就会转化SqlNode,然后生成一个未经验证的抽象语法树 |
| RelNode | relational expression,SqlNode 经过语法分析就会生成RelNode | 代表了对数据的一个处理操作,常见的操作有 Sort、Join、Project、Filter、Scan 等。它包含了对整个 Relation 的操作,而不是对具体数据的处理逻辑。 |
| RelOptRule | transforms an expression into another。对 expression 做等价转换 | 根据它里面的一些规则来对目标 RelNode 树进行局部规则匹配,匹配成功后,则调用 onMatch() 方法进行转换。 |
| ConverterRule | 规则的抽象类,该规则从一种调用规则转化为另一种调用规则而无需更改语义 | 它是 RelOptRule 的子类,专门用来做数据源之间的转换(Calling convention),ConverterRule 一般会调用对应的 Converter 来完成工作,比如说:JdbcToSparkConverterRule 调用 JdbcToSparkConverter 来完成对 JDBC Table 到 Spark RDD 的转换。 |
| Converter | A relational expression implements the interface Converter to indicate that it converts a physical attribute, or RelTrait of a relational expression from one value to another. |
用来把一种 RelTrait 转换为另一种 RelTrait 的 RelNode。如 JdbcToSparkConverter 可以把 JDBC 里的 table 转换为 Spark RDD。如果需要在一个 RelNode 中处理来源于异构系统的逻辑表,Calcite 要求先用 Converter 把异构系统的逻辑表转换为同一种 Convention。 |
| RexNode | Row-level expression行表达式 | 行表达式(标量表达式),蕴含的是对一行数据的处理逻辑。每个行表达式都有数据的类型。这是因为在 Valdiation 的过程中,编译器会推导出表达式的结果类型。常见的行表达式包括字面量 RexLiteral, 变量 RexVariable, 函数或操作符调用 RexCall 等。 RexNode 通过 RexBuilder 进行构建。 |
| RelTrait | RelTrait表示特征定义中关系表达式特质的表现形式 | 用来定义逻辑表的物理相关属性(physical property),三种主要的特征类型是:1、Convention(用于表示单个数据源的调用约定,一个 relational expression 必须在同一个 convention 中)、2、RelCollation(指的是该关系表达式所定义的数据的排序)、3、RelDistribution(标识数据的分布特点,比如single、hash、range、random等); |
| RelTraitDef | 主要有三种:ConventionTraitDef:用来代表数据源 ;RelCollationTraitDef:用来定义参与排序的字段;RelDistributionTraitDef:用来定义数据在物理存储上的分布方式(比如:single、hash、range、random 等); | |
| RelOptCluster | An environment for related relational expressions during the optimization of a query. | palnner运行时的环境,保存上下文信息; |
| RelOptPlanner | A RelOptPlanner is a query optimizer: it transforms a relational expression into a semantically equivalent relational expression, according to a given set of rules and a cost model. | 也就是优化器,Calcite 支持RBO(Rule-Based Optimizer) 和 CBO(Cost-Based Optimizer)。Calcite 的 RBO (HepPlanner)称为启发式优化器(heuristic implementation ),它简单地按 AST 树结构匹配所有已知规则,直到没有规则能够匹配为止;Calcite 的 CBO 称为火山式优化器(VolcanoPlanner)成本优化器也会匹配并应用规则,当整棵树的成本降低趋于稳定后,优化完成,成本优化器依赖于比较准确的成本估算。RelOptCost 和 Statistic 与成本估算相关; |
| RelOptCost | defines an interface for optimizer cost in terms of number of rows processed, CPU cost, and I/O cost. | 主要依赖于IO、CPU、RowCount、memory |
关系代数
关系
关系是关系模型中用于描述数据的主要结构。包括关系模式(relation schema)和关系实例(relation instance)。
关系实例:一个二维表。
关系模式:对表的每个列进行描述。
例如:
Students(sid:string, name:string, age:integer)。一个关系代数表达式可以用关系、一元或二元代数操作符来递归定义。代数操作符的输入和输出都是关系实例。
关系代数
关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。
关系代数也是 Calcite 的核心,任何一个查询都可以表示成由关系运算符组成的树。在 Calcite 中,它会先将 SQL 转换成关系表达式(relational expression),然后通过规则匹配(rules match)进行相应的优化,优化会有一个成本(cost)模型为参考。
优化器
优化器的作用将解析器生成的关系代数表达式转换成执行计划,供执行引擎执行,在这个过程中,会应用一些规则优化,以帮助生成更高效的执行计划。SQL 查询优化器分为两种类型:
RBO
- HepPlanner 是一个启发式优化器;
- 将会匹配定义的所有 rules 直到一个 rule 被满足;
- 相比CBO优化器更快;
- 如果没有每次都不匹配规则,可能会有无限递归风险;
- 规则是基于经验的,经验就可能是有偏的,总有些问题经验解决解不了。
CBO
- VolcanoPlanner是一个代价优化器;
- 迭代应用 rules,直到找到cost最小的plan;
- 成本由关系表达式提供;
- 不会计算所有可能的计划;
- 根据已知的情况,如果下面的迭代不能带来提升时,这些计划将会停止优化。
- CBO 中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响CBO选择最优计划。
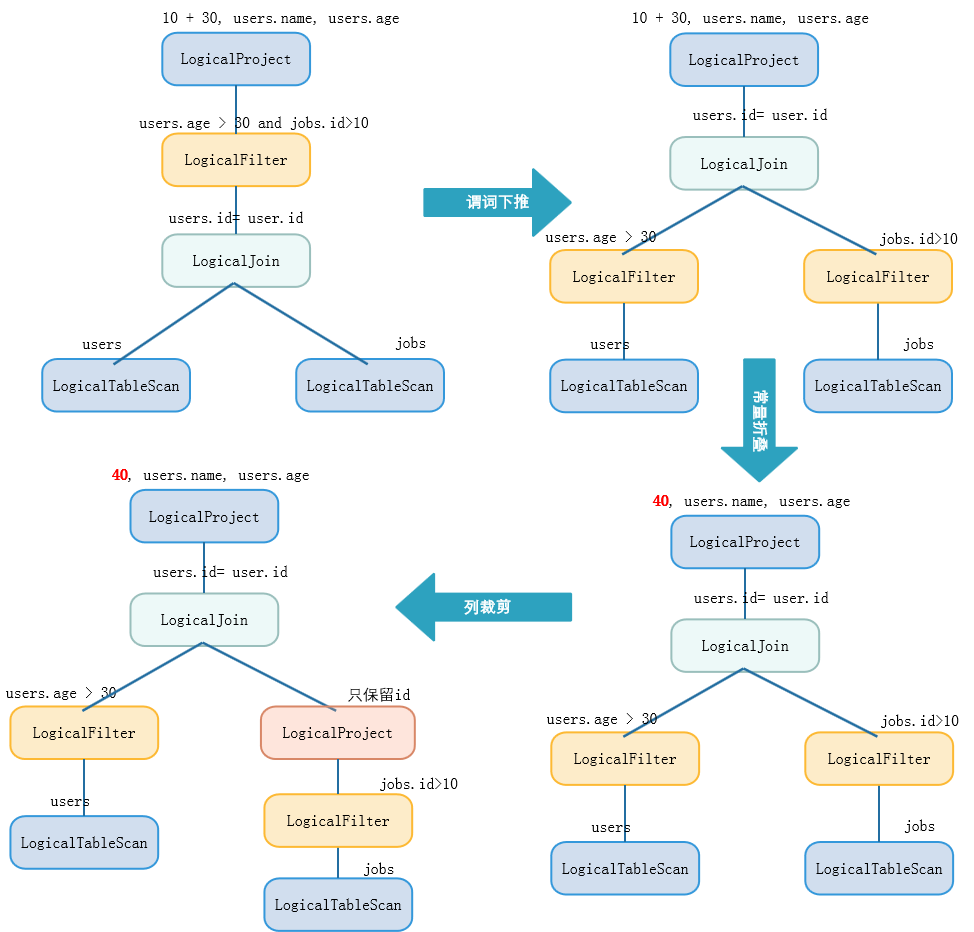
无论是 RBO,还是 CBO 都包含了一系列优化规则,这些优化规则可以对关系表达式进行等价转换。常见的优化规则包含:谓词下推 Predicate Pushdown、常量折叠 Constant Folding、列裁剪 Column Pruning等等。见如下实例:
1 | select 10+30, users.name, users.age |
优化过程如下图所示:
代价模型
代价模型指的用于计算Cost来选择最优的执行计划,一个好的代价模型可能会影响整个系统的性能。其中,
- Calcite代价模型
1 | public boolean isLe(RelOptCost other) { |
Ali的MaxComputer代价模型
涉及的指标有:CPU、IO、RowCount、Memory、NetWork
适配器
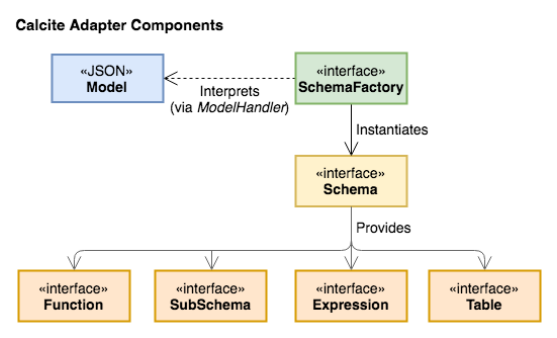
Schema&Catalog
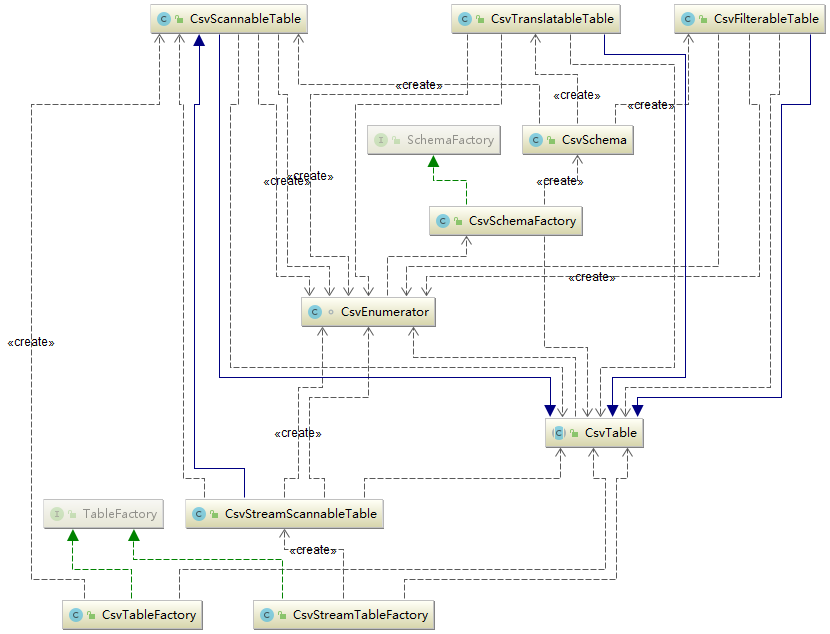
用户通过使用SchemaFactory和Schema interfaces来自定义schema。以JSON模型文件声明schemas或者views。通过Table interface自定义table。定义table的record类型。三种表类型:
- 使用ScannableTable interface作为Table的简单实现,来直接枚举所有的rows;
- 进阶实现FilterableTable,来根据简单的谓词predicates过滤rows;
- 以TranslatableTable进阶实现Table,将关系型算子转换为执行计划规则;
- 扩展了CsvStreamScannableTable继承于Scannable Table,流的扩展,即STREAM扩展,窗口扩展,通过联接中的窗口表达式对流的隐式引用等,为流查询提供了支持。
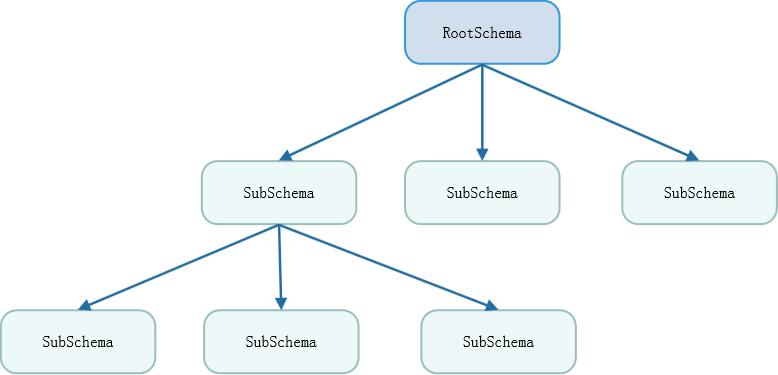
Catalog主要定义SQL语义相关的元数据与命名空间。Calcite利用schema的层级关系,构造出来namespace的概念,如图所示,schema自身是一个树形结构,这样设计的优点很明显,可以兼容所有已知和未知的数据库,基于namespace结构,schema无论是横向还是纵向都可以无限扩展。
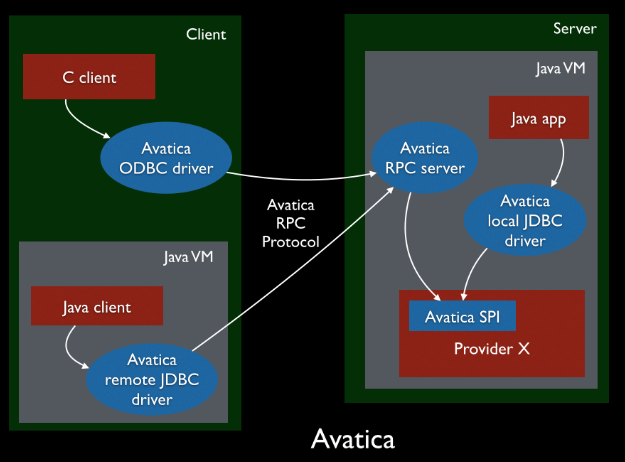
Avatica
JDBC驱动程序由Avatica提供支持。Avatica是用于为数据库构建JDBC和ODBC驱动程序以及RPC协议的框架。连接可以是本地连接或远程连接(基于HTTP的JSON或基于HTTP的Protobuf)。JDBC连接字符串的基本形式jdbc:calcite:property=value;property2=value2。
CSV适配器示例
扩展结构
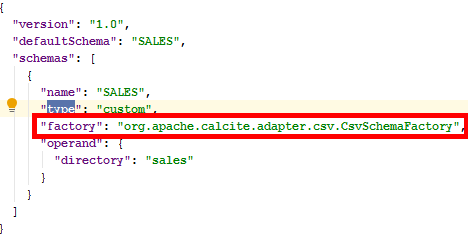
配置信息
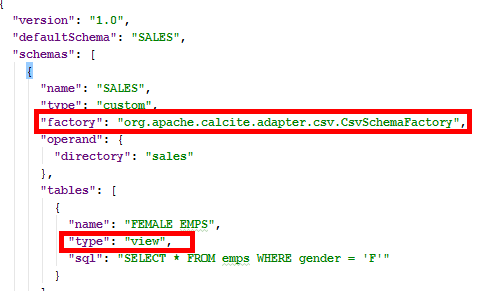
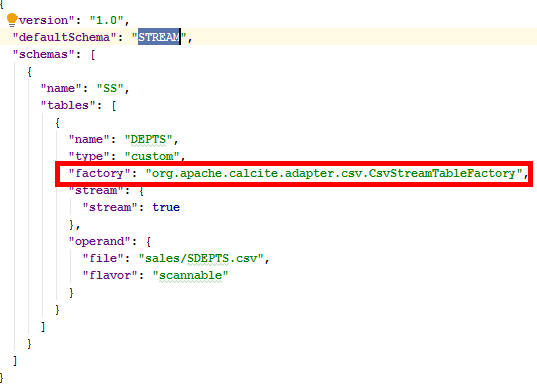
扩展功能
Lin4j
Linq4j(Language-Integrated Query for Java),Calcite可以用于查询多个数据源,而不仅仅是关系数据库。但是,它的目的还不仅仅是支持SQL语言。尽管SQL仍然是主要的数据库语言,但许多程序员还是喜欢LINQ等语言集成语言。与Java或C ++代码中嵌入的SQL不同,语言集成的查询语言允许程序员使用一种语言编写所有代码。 Calcite提供Java语言集成查询(简称LINQ4J),该查询紧密遵循Mirosoft的LINQ为.NET语言制定的约定。
GeoSpatial
地理空间支持在Calcite中是初步的,使用Calicte的关系代数来实现。 此实现的核心在于添加新的GEOMETRY数据类型,该数据类型封装了不同的几何对象,例如点,曲线和多边形。 预计Calcite将完全符合OpenGIS Simple Feature Access 规范,该规范定义了SQL接口访问地理空间数据的标准。
开源项目应用
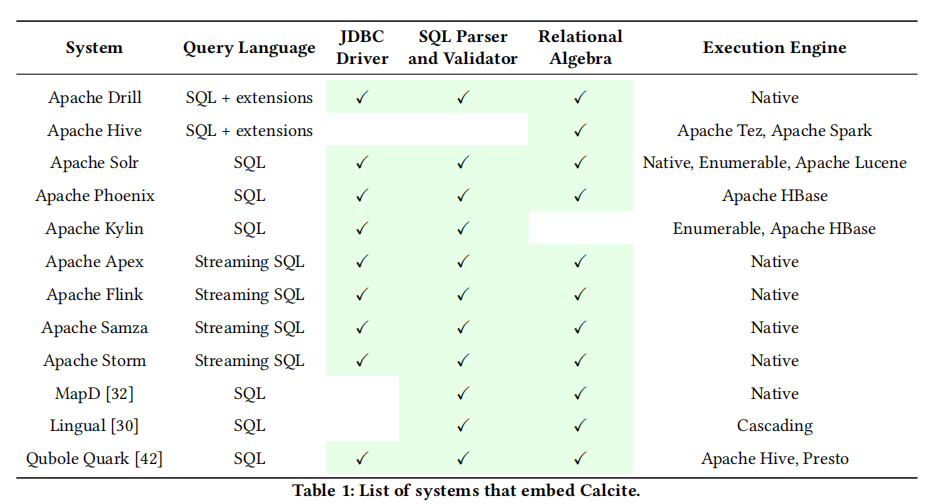
Hive
Calcite灵活可插拔的架构,使得Hive可以完全使用自己独立的SQL Parser和Validator,而只用 Calcite 的 Query Optimizer。而Hive在代码层面和 Calcite 的结合体现在 CalcitePlanner 这个类:
1 | public class CalcitePlanner extends SemanticAnalyzer { |
在Hive看来,CPU和 IO应该优先级比行数更高,先比较这俩,如果相等,才去看行数。而CPU和IO就不用分那么清楚了,合一起就行,怎么合呢,直接相加。
1 | public class HiveVolcanoPlanner extends VolcanoPlanner { |
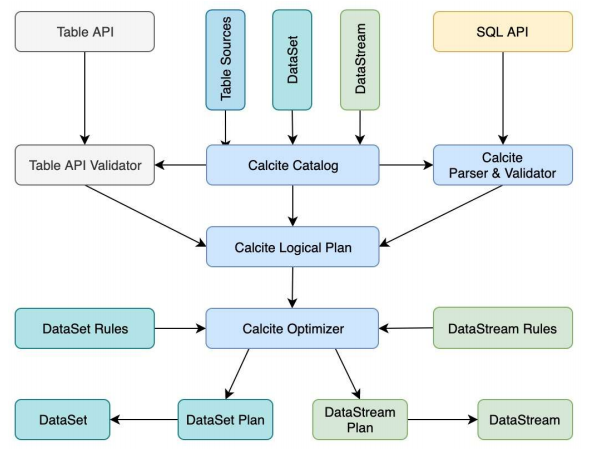
Flink
Flink 以Calcite Catalog 为核心,上面承载了 Table API 和 SQL API 两套表达方式,最后殊途同归,统一生成为 Calcite Logical Plan(SqlNode 树);随后验证、优化为 RelNode 树,最终通过 Rules(规则)和 Convention(转化特征)生成具体的 DataSet Plan(批处理)或 DataStream Plan(流处理),即 Flink 算子构成的处理逻辑。
未来发展
Calcite的未来工作将集中在新功能的开发以及其适配器体系结构的扩展上:
- 改进Calcite的设计以进一步支持其使用独立引擎,这将需要对数据定义语言(DDL),物化视图,索引和约束的支持;
- 不断改进计划程序的设计和灵活性,包括使其更具模块化,从而使用户Calcite可以提供计划程序(规则的集合或合并为计划阶段)以执行;
- 将新的参数化方法[多目标参数化查询优化]纳入优化器的设计;
- 支持扩展的SQL命令,功能和实用程序集,包括完全符合OpenGIS;
- 用于非关系数据源的新适配器,例如用于科学计算的阵列数据库;
- 改进了性能分析和检测。