Calcite原理和经验总结
概述
Calcite(最初被命名为optiq,由Julian Hyde编写,之后成为apache项目)是一个动态数据管理框架,不考虑数据的存储、处理数据的算法以及元数据的保存问题,只保留了重要的数据库管理功能,成为应用程序和多个数据源交互的中介。
Optiq起初在Hive项目中,为其提供成本优化模型,即CBO(Cost Based Optimization)。它是面向Hadoop新的查询引擎,提供了OLAP和流SQL查询引擎。当前,还应用于Flink解析和流SQL处理、Drill的解析和JDBC接口等、Kylin的OLAP。
Calcite的目标是一种方案适应所有需求场景(one size fits all),希望能够为不同计算平台提供统一查询引擎,让访问hadoop上的数据跟传统数据库访问方式一样(SQL和高级查询优化)。
主要特性
- SQL解析、验证和优化,支持标准函数和聚合函数,提供JDBC驱动查询能力;
- 连接不同前端(SQL、Pig等翻译为关系代数)和不同后端(适配器对接各种存储接口);
- 支持关系代数、定制逻辑规则和基于CBO和RBO优化的查询引擎;
- 物化视图管理以及物化视图Lattice和Tile机制来应用于OLAP分析;
- 支持对流数据的查询。
基本原理
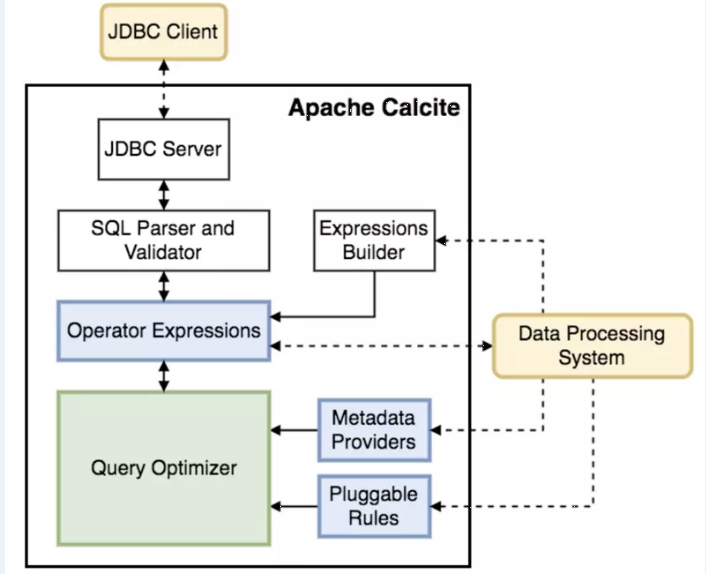
Calcite框架中的主要接口,都可以单独被集成使用。例如:
- 提供JDBC接口实现、SQL的解析和元数据校验、关系代数转换为执行计划(CBO和RBO)等;
- JDBC Client对外通过驱动类加载访问JDBC Server, Server服务通过Jetty对外提供;
- SQLParser将SQL解析成SqlNode,并通过Validator验证SqlNode信息;Operator Exp将SqlNode转为RelNode树
- QueryOptimizer将RelNode基于规则或成本优化执行计划。
示例解析
执行SQL:select a,b,c from tab where a = 11
2
3--LogicalFilter
----LogicalProject
------LogicalTableScan
优化方式:
1)RBO:预先定义一些规则,来优化执行计划(HepPlanner)
比如先过滤,再投影,可以减小数据量,优化如下:1
2
3--LogicalProject
---- LogicalFilter
------LogicalTableScan
2)CBO: 计算SQL所有可能执行的代价,选择一个代价较低(VolcanoPlanner)
计算LogicalProject、LogicalFilter、LogicalTableScan转为不同的执行计划所具有的代价,选择不是最坏的、相对较小的。
实战总结
以上介绍了Calcite的基本特性和原理,以及在大数据计算引擎领域的应用情况。以下是本人在实际使用过程中(1.5版本),遇到的一些坑,方便遇到同样问题的开发者排查问题。
- 对于应用程序已经打开的JDBC连接,新增的表无法感知,需要重新建立连接,重新加载元数据;
- 对于长度很长的大SQL,在翻译为物理执行计划(对接底层存储引擎的处理逻辑)时,有可能会超过Janino约束的64KB大小,导致物理计划生成失败;
- 对于大SQL中的组合条件嵌套不可以太深,否则会导致SQL解析器报栈溢出;
- Calcite作为计算框架的SQL引擎,除了下推到底层存储的算子操作,其他都是在内存中计算的,因此对资源的要求比较高;
- 同样的SQL或者预编译SQL生成的物理执行计划,目前发现JVM装载完成后并没有复用,持续的查询反而造成了方法区Class暴增,导致permgen overflow。然后,修改源码将每次创建的Statement强制关闭,使得FullGC时Class可以被unload,避免permgen overflow。(该问题17年csdn上提问,18年有网友回复)