Drill性能识别和调优
引言
本文的内容来自DRILL的官方提供的性能识别和调优指南。
查询计划和调整
介绍
DRILL可以修改很多配置来影响如何计划一个查询。这里将介绍一些配置的修改来提升性能。
Join计划
DRILL使用分布式和广播join来关联表,可以修改如下配置项来控制drill来生成join计划。
分布式join
针对分布式join,在join的两侧都是hash分布的,使用基于hash分布操作集的其中一个在join的key上。如果每个表中有多个join key,则drill将考虑以下两种类型的计划:
- 在所有键上分布数据的计划;
- 在每个单独的键上分发数据的计划。
对于merge join,drill在执行hash分布之后对join的两侧进行排序。drill可以分布hash join和merge join的两侧,但是nested loop join不可以。
广播join
在广播join中,join之前所有选中的数据记录被广播到其他节点。join的内部被广播而外部保持不动没有分发。内部预估的基数必须小于planner.broadcast_threshold参数设定的值才有资格进行广播。drill针对hash join、merge join和nested loop join都可以使用broadcast join。
当一个大表关联一个小表时广播join是比较有用的。如果大表在分布式文件系统中保存了很多文件,不用基于网络重新分布大表数据,直接广播小表数据也许廉价得多。然而,广播会发送同样的数据到集群所有其他节点。取决于集群的大小和数据大小,在某些场景下也许并不是最有效的策略。
广播join的配置项
你可以采用ALTER SYSTEM或者ALTER SESSION的方式修改drill使用广播join的参数大小和系数。一般,在会话级别设置配置项,除非你想在所有session中生效。以下配置项可以控制广播join的行为:
planner.broadcast_factor: 当执行join时控制广播的成本。这个值越小,广播join相比于其他分布式join(如hash分布)成本更低。默认值为1,范围为0-1.7976931348623157e+308。planner.enable_broadcast_join:改变aggregation和join操作的状态。广播join可以用于hash join、merge join以及nested loop join。广播join用于大表关联小表。planner.broadcast_threshold:一个阀值,数据行数,决定了一个查询是否要使用广播join。不管广播join是否开启,只有join右侧预估的数据行数小于阀值才会选择广播join。这个配置项的目的是为了避免广播太多的数据,因为广播涉及跨节点发送数据和网络密集型操作。join的右侧可能是一个join或者一个简单的table,取决于物理计划期间的基于成本的优化和启发式方法。默认值为10000000,范围为0-2147483647。
Aggregation优化
针对包含GROUP BY的查询,drill执行聚合在1阶段或者2阶段。在这两种计划中,drill可以使用hash join或streaming join的物理操作。drill中默认操作是执行2阶段聚合。
在2阶段聚合方式中,每个minor fragment在1阶段执行本地或部分聚合,它将部分聚合的结果发送到其他fragments,通过基于hash的分布操作。hash分布式是按照GROUP BY的key完成的。在第2阶段所有fragments使用来自阶段1的数据进行总体聚合。
当GROUP BY的keys数据有合理数量的重复值时,2阶段聚合的方式是比较有效的,因为分组可以减少发送到下游操作集的数据行数。然而,如果没有太多的减少,则最好使用1阶段聚合。
例如,假设GROUP BY x,y的查询,在输入的数据中{x, y}的组合值时唯一的(或近似唯一),这种情况执行GROUP数据行没有减少,使用1阶段聚合可以提升性能。
你可以使用ALTER SYSTEM或ALTER SESSION命令设置配置来控制drill的聚合:
planner.enable_multiphase_agg:默认值为true。
修改Query计划
Planner配置项会影响drill如何计划一个查询。通过ALTER SYSTEM或ALTER SESSION命令设置,配置如下:
planner.width.max_per_node配置此选项,获取并行度的细粒度绝对控制。在这个上下文中,width指扇出(fan out)或分布(distribution)潜力,即在节点的core上和集群的节点上并行运行查询的能力。一个物理计划由中间操作(称为查询片段)组成,这些操作能够并发运行,在计划每个exchange操作之上和之下产生并行的机会。一个exchange操作代表了执行流中的一个断点,这个断点是可以分发处理的。例如,文件单线程扫描流向exchange操作,然后是多线程聚合片段。
每个节点的最大width定义了一个查询中任何片段的最大并行度,但是这个是作用在一个集群的单个节点上。默认每个节点的最大并行度计算方式如下:理论最大值自动缩回(和舍入),使得只有实际可用容量的70%被考虑:
活跃drillbit数(一般一个节点一个)* 每个节点核数 * 0.7。例如,一个单节点2核测试系统并开启超线程:
1 * 4 * 0.7 = 3。当你修改这个默认值时,可以提供任何有意义的数值,此时系统将不会自动缩小你的设置。planner.width_max_per_query默认值是1000。一个查询跨所有节点并行运行的最大线程数。仅当drill在非常大的集群上并行时更改此设置。
planner.slice_target默认值是100000。在使用额外并行化之前,在major fragment中工作的最小预估记录数。
planner.broadcast_threshold默认值是10000000。作为join的一部分,可以被广播的最大记录数。当达到这个阈值时,drill将采用reshuffles而不是广播。你可以增加这个值来提升性能(尤其在10GB以太网集群上)。
基于排序和基于hash的内存限制操作集
Drill支持以下内存密集型操作集,如果这些操作集耗尽内存,会将数据临时溢写到磁盘:
- External Sort
- Hash Join (Semi Join,出现在IN或EXISTS中的子查询,用于outer_table过滤)
- Hash Aggregate
Drill仅仅使用External Sort算子来排序数据,使用Hash Aggregate算子来聚合数据。可替代方法,Drill可以对数据排序,然后使用(轻量)的Streaming Aggregate算子来聚合数据。
Drill使用Hash Join算子来关联数据,在1.15版本将Semi Join引入Hash Join算子来提升查询性能。Semi Join移除了Hash Join下的去重处理,并消除使用Hash Aggregate产生的开销。在1.15版本之前或者关闭Semi Join功能,Drill使用去重Hash Aggregate来实现Semi Join的功能。可替代方法,Drill使用Nested-Loop-Join或者对数据进行排序再使用(轻量)Merge-Join。Drill一般使用hash算子来进行关联和聚合,它们比排序算子有更好的性能(Hash和Sort的时间复杂度分别为O(N)和O(N * log(N)))。然而,如果你关闭Hash算子或者数据已经排好序,Drill将使用前面描述的替代方法。
Drill中的内存配置可以为每个查询、每个节点的内存进行限制。分配的内存在可溢出算子的所有实例中平均分配(每个节点上的每个查询)。实例的数量 = 查询计划中的可溢出算子数量 * 最大并行度。最大并行度 = 为可溢出算子的每个实例执行工作的minor fragment的数量。当一个可溢出算子的实例必须处理更多的数据,超过它内存所能存放的,这个算子会临时溢写一些数据到磁盘目录来完成整个工作。
溢写到磁盘
溢写到磁盘可以避免内存密集型操作因为内存耗尽而失败。当算子的内存要求超过设置时,溢写磁盘的特性可以使可溢写算子自动将多余的数据写到磁盘的临时目录。当算子在后台执行溢写操作时,查询不会间断。
当可溢写算子完成内存数据的处理后,会将磁盘中数据读回完成数据的处理,之后清除溢写位置的数据。
理想情况下,可以分配足够的内存,为Drill在内存中执行所有的操作。当数据溢写到磁盘,并不会看到查询运行的差异,然而溢写到磁盘会影响性能,因为写到磁盘再从磁盘读取,会产生额外的IO。
(1) 溢写位置
溢写的默认位置是/tmp/drill/spill 。这个目录适合小的负载和示例来用。因此,需要重新设置溢写的位置,有足够的磁盘空间来支撑大的工作负载。
备注:溢出的数据可能需要更大的空间,相比查询中涉及的表引用的数据。例如,当底层表数据是压缩的(ORC、Parquet)或者算子接收的数据要join多张表。
当你配置溢写位置,可以设置单个目录或目录列表给可溢出算子使用。
(2) 溢写磁盘配置
在配置文件drill-override.conf中可以设置溢写位置,管理可以更改文件系统以及目录列表。配置项如下:
drill.exec.spill.fs:默认的文件系统是本地机器,file:///。也可以配置分布式文件系统,比如hdfs:///;drill.exec.spill.directories:默认是["/tmp/drill/spill"]。也可以配置为["/fs1/drill/spill","/fs2/drill/spill"]。
内存分配
Drill在可溢出算子的所有实例之间均匀地分割可用内存。当查询被并行化时,算子的数量将会成倍增加,这会减少查询期间为算子的所有实例提供的内存数量。要查看算子之间内存消耗差异,可以运行查询,在Drill Web UI中查看query profiles。或者,关闭hash算子,强制Drill使用Merge Join和Streaming Aggregate。
(1) 内存分配配置
planner.memory.max_query_memory_per_node:drill在一个节点上每个查询可使用的最小内存,默认是2GB,在JVM的Direct Memory默认值为8GB的情况下,可以到2-3个并发。当Drill的内存要求增加,默认的2GB被约束,必须要添加这个值大小才能完成查询。除非planner.memory.percent_per_query设置允许Drill使用更多的内存。planner.memory.percent_per_query另外一种方式,这个配置设置为总Direct Memory的百分比,默认值是5%。当throttling关闭时这个值才会使用,设置为0时关闭该选项。可以增加或减少该值,但是要将百分比设置在远低于JVM Direct Memory的位置,因为要考虑Drill不管理内存的情况,例如内存密集度较低的算子。
- 计算公式如下:(1 - non-managed allowance) / concurrency
- non-managed allowance是non-managed算子使用的假设系统内存。non-managed算子不会溢写到磁盘。non-managed allowance的保守假设是系统内存的50%。concurrency是并发查询的数量。默认假设是10个并发查询。
(2) 增加可获得的内存
1 | ALTER SYSTEM | SESSION SET `planner.memory.max_query_memory_per_node`= new_value |
关闭Hash算子
可以关闭hash聚合和hash join的算子。当关闭这些算子之后,Drill会创建一个替代查询计划,采用Sort算子和Streaming聚合/Merge Join算子。配置项如下:
planner.enable_hashagg: 开启或关闭hash聚合,关闭后Drill采用基于Sort的聚合。默认是开启的,推荐开启。在Drill 1.11版本之前,hash聚合算子内存不受控制(达到10GB),然后就耗尽内存。从这个版本之后,支持溢写到磁盘;planner.enable_hashjoin: 开启或关闭hash关联,默认是开启的。Drill假设一个查询有足够的内存来完成,则会尝试使用最可能快的操作。Drill 1.14版本之前,Hash Join算子使用不受控制的内存(达到10G),然后就耗尽内存。从这个版本之后,这个算子支持溢写到磁盘;planner.enable_semijoin: 开启或关闭Hash Join的Semi Join功能,默认是开启的。开启后,Hash Join中的semi-join标记设置为true。Drill使用semi-join来去除Hash Join下的不同处理。关闭后,Drill还是可以执行semi-join,但是semi-join将会Hash Join的外部执行,如下示例所示:- Semi Join关闭
1
2
3
4
5
6
7
8
9
10
11
12explain plan for
select employee_id, full_name
from employee where employee_id IN (select employee_id from employee);
screen
project(employee_id=[$0], full_name=[$1])
project(employee_id=[$0], full_name=[$1])
HashJoin(condition=[=($0, $2)], joinType=[inner], semi-join: =[false]) --哈希连接
scan(...)
project(employee_id0=[$0])
HashAgg(group=[$0]) -- 去重使用
scan(...)- Semi Join开启
1
2
3
4
5
6
7
8
9
10explain plan for
select employee_id, full_name
from employee where employee_id IN (select employee_id from employee);
screen
project(employee_id=[$0], full_name=[$1])
project(employee_id=[$0], full_name=[$1])
HashJoin(condition=[=($0, $2)], joinType=[inner], semi-join: =[true]) --半连接
scan(...)
scan(...)
开启查询队列
Drill默认允许并发查询,但是当少量并发查询时,Drill性能会有所提高。开启查询队列来限制并发运行查询的最大数量。将大查询拆分为多个小查询并开启查询队列可以提高查询性能。
当你开启查询队列,你可以配置大队列和小队列。Drill根据查询的大小,将查询路由到哪个队列。Drill能够快速完成查询,继续执行下一组查询。
请看如下示例:
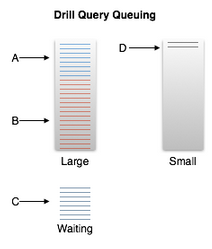
A查询(蓝色部分):10亿条记录,预估1000万行数据处理;
B查询(红色部分):20亿条记录,预估2000万行数据处理;
C查询:10亿条记录;
D查询:100条记录;
exec.queue.threshold是3000万作为查询预估处理行数。因此,A和B属于large query,在large queue中排队。当预估处理的行数达到3000万的阀值时,A和B的查询已经填满了队列。之后C查询到来,只能等待。D查询到来理解进入small queue中。
相关配置如下:
exec.queue.enable: 默认关闭。开启后,控制同时运行的查询数量。exec.queue.large: 默认为10,范围为0-1000。设置集群中大查询并发数量。exec.queue.small: 默认为100,范围为0-10001。exec.queue.threshold: 决定一个查询是否为large还是small的。复杂查询有更高的值。默认为30000000,范围为0-9223372036854775807。exec.queue.timeout_millis: 表示一个查询在队列等待的时间在失败之前。默认为300000,范围为0-9223372036854775807。exec.queue.memory_ratio: 默认情况下,大查询使用的内存是小查询的10倍。如果实际过程中,发现其他值效果更好,则可以调整这个比例来满足实际的查询。exec.queue.memory_reserve_ratio: 还有Sort和Hash聚合算子要观察内存限制,溢写到磁盘。其他算子没有被管理,所需的内存量因您的特定查询而异。考虑到这些算子,需要预留一些内存。默认值是20%。但是重Join工作负载可能需要更大的值,比如50%甚至更多。
限流
Drill 1.12版本引入限流。限流限制了并发查询的数量,防止内存耗尽导致查询失败。当开启限流后,可以控制并发查询的数量和每个查询的资源要求。Drill会为每个节点和每个查询计算要分配的内存量。
如果限流关闭,可能需要增大planner.memory.max_query_memory_per_node的可分配内存。Drill必须决定为每个算子分配多大的内存,但不知道可能运行多少并发查询。如果Drill不能给Sort和Hash聚合算子足够的内存,查询将会失败。此时,就需要开启限流防止这种情况的发生。
限流配置
小队列和大队列的计算方式:
1 | memory unit = small_queue + (large_queue * memory_ratio) |
调校
通过查看query profiles来决定正确的参数:
- 设置队列大小保守一些确保查询成功;
- 做实验,通过观察典型的查询的实际开销来调整队列阀值;
- 如果由于Join等操作导致OOM发生,请调整内存设置。
识别性能问题
查询计划
如果在Drill中遇到性能问题,你通常能够在query plan或query profiles中识别问题来源。本小节介绍逻辑计划和物理计划。
Drill有一个优化器和并行器一起工作来计划一个查询。Drill基于相关文件或数据源的统计信息来创建逻辑计划、物理计划以及执行计划。Drill的运行节点数量以及运行时配置有助于Drill如何计划执行一个查询。
我们可以通过执行explain命令来查看逻辑计划和物理计划,当时执行计划看不到,可以通过8047界面查看query profile。
逻辑计划
一个逻辑计划是一系列逻辑算子的集合,描述了要生成的查询结果、定义的数据源和应用的算子。Drill的解析器将SQL算子转为逻辑算子语法,Drill理解后创建逻辑计划。你可以通过逻辑计划看到这些计划算子集。通过submit_plan命令,将修改后的逻辑计划重新提交给Drill,但这个作用并不是很大,因为计划阶段Drill还不能决定并行度。
物理计划
一个物理计划描述了针对查询语句被选中的物理执行计划。优化器会应用多种规则重新安排算子和函数,形成一个优化的计划,然后将这个逻辑计划转为物理计划,告知Drill如何执行一个查询。
你可以重新评审一个物理执行计划中的问题,修改这个计划,再次提交给Drill。比如,你遇到转换错误或者你想改变表的join的顺序看是否查询会更快。你可以修改物理计划来解决问题,提交给Drill来执行查询。
Drill将物理计划转为minor fragments的执行树,在集群上并发运行来执行任务(参见query execution)。你可以在query profile中查看fragments执行查询的活动(参见query profiles)。
查看物理计划
物理计划显示major fragments和与major fragment ids、operator ids相关的指定算子。Major fragments是一个抽象概念表示查询执行的一个阶段,不执行任何任务。
物理计划中的展示的ID格式:<MajorFragmentID> - <OperatorID>
Query Profiles
一个profile是Drill每个查询收集的metrics信息的摘要。Query Profiles提供的信息,我们可以用来监控和分析查询性能。当Drill执行查询,会将每个查询的profile写入到磁盘,本地文件系统或分布式文件系统。在Drill 1.16版本中,如果有问题会影响性能,Web UI展示了告警信息。
query profile
- STATE(查询状态):running、completed、failed;
- FOREMAN(协调器): drillbit接收到来自客户端或应用的查询后,节点作为foreman来运行,驱动整个查询;
- Total Fragments: 要求在执行的minor fragment的总数量。
标示符构成
query profile文件中的metrics和标示符的坐标系相关联。Drill使用由query、fragment和operator标示符构成的坐标系来跟踪查询执行的活动和资源。Drill分配一个唯一标示符Query ID,给每个接收到的查询,然后给每个fragment和operator分配ID。示例如下:
1 | MajorFragmentID-MinorFragmentID-OperatorID |
当Drill执行一个查询时,工作负载应该被统一分布到fragment和operator中来处理数据。当你评估query profile时,看到fragment的处理时间不成比例的分布或者内存的过度使用,一般表明性能存在问题,要求性能调优。比如:
- 一定时间内查询没有进度;
- 算子有数据溢写到磁盘(没有足够内存完成整个操作);
- 算子花在等待数据的时间远远大于处理数据的时间。
下面列出,其他的一些告警信息:
告警阈值设置
通过drill-override.conf设置,如下所示:
1 | http: { |
物理计划视图
物理计划视图提供了统计信息,一个查询操作的实际成本,包括memory、IO以及CPU。可以通过这个信息识别查询期间操作消耗的主要资源。
性能调优参考
Query Profile描述
Fragment 概览表格
| 列名 | 描述 |
|---|---|
| Major Fragment ID | major片段坐标ID。例如,03-xx-xx。其中03是主片段ID,后面两位分别代表minor片段ID和算子ID。 |
| Minor Fragments Reporting | 为major片段并行化的minor片段数量 |
| First Start | 第一个minor片段开始任务前的总时间 |
| Last Start | 最后一个minor片段开始任务前的总时间 |
| First End | 第一个minor片段完成任务的总时间 |
| Last End | 最后一个minor片段完成任务的总时间 |
| Min Runtime | minor片段完成任务花费总时间的最小值 |
| Avg Runtime | minor片段完成任务花费总时间的平均值 |
| Max Runtime | minor片段完成任务花费总时间的最大值 |
| Last Update | minor片段发送更新状态给foreman最后一次时间。时间24小时制表示。 |
| Last Progress | minor片段进度变化的最后一次时间,如fragment状态或从磁盘读数据。时间24小时制表示。 |
| Max Peak Memory | 所有minor片段中申请direct memory的最大峰值 |
Major Fragment块
展示每个major片段中minor片段被并行化的度量信息。
| 列名 | 描述 |
|---|---|
| Minor Fragment ID | major片段中被并行化的minor片段坐标ID。例如,02-03-xx,02是major片段ID,03是minor片段ID,xx是算子ID。 |
| Host | minor片段执行任务所在的节点 |
| Start | minor片段开始任务之前经过的时间 |
| End | minor片段完成任务之前经过的时间 |
| Runtime | fragment完成任务的持续时间。这个值是End-Start |
| Max Records | 算子从单个输入流中消耗的最大记录数 |
| Max Batches | 跨输入流、算子以及minor片段的最大输入批次数 |
| Last Update | fragment发送更新状态给foreman最后一次时间 |
| Last Progress | fragment产生进度,比如状态变化、从磁盘读数据的最后一次时间 |
| Peak Memory | minor fragment执行期间分配德尔direct memory的峰值 |
| State | minor fragment的状态,完成、运行、取消或失败 |
Operator 概览表格
显示的是在执行查询期间一个major片段执行关系操作中每个算子的聚合度量信息。
| 列名 | 描述 |
|---|---|
| Operator ID | 在查询的一个特定阶段,一个执行操作的算子坐标ID。比如02-xx-03,02是major片段,xx是对应minor片段,03是算子ID。 |
| Type | 算子类型,如project、filter、hash join、single sender或者unordered receiver。 |
| Min/Avg/Max Setup Time | 在执行操作之前,算子setup所花费的最小、平均和最大时间 |
| Min/Avg/Max Process Time | 算子执行操作所花费的最小、平均和最大时间 |
| Wait(Min/Avg/Max) | 算子等待外部数据源所花费最小、平均和最大时间 |
| Avg Peak Memory | 在minor fragment中分配direct memory的平均峰值。跟算子执行操作所需的内存有关,比如hash join或sort。 |
| Max Peak Memory | 在minor fragment中分配direct memory的最大峰值。跟算子执行操作所需的内存有关,比如hash join或sort。 |
Operator 块
显示每个major片段中每个操作类型时间和内存度量。
| 列名 | 描述 |
|---|---|
| minor fragment | 算子所在的minor fragment坐标ID。例如,04-03-01,04是major fragment ID,03是minor fragment ID,01是算子ID。 |
| Setup Time | 算子执行操作之前的启动时间,包含runtime code的生成和打开文件 |
| Process Time | 算子执行操作的时间 |
| Wait Time | 算子等待外部数据源的时间,比如等待发送记录,等待接收记录,等待写入磁盘,等待从磁盘读取。 |
| Max Batches | 从单个输入流消费的最大记录批次 |
| Max Records | 从单个输入流消费的最大记录数量 |
| Peak Memory | 代表分配的direct memory峰值。跟算子执行操作所需要的内存有关,比如hash join或sort。 |
物理算子
分发算子
以下算子在网络中执行数据分布:
| 算子 | 描述 |
|---|---|
| HashToRandomExchange | 获取一个输入行,基于分布的key计算hash值,然后基于hash值决定终端接收器,在一个batch的操作中发送该行。分布的key可以是join key或者group by聚合的key。目标接收器是目标节点上的一个minor fragment。 |
| HashToMergeExchange | 和HashToRandomExchange类似,只是每个目标接收器合并来自发送者的排序后的数据。 |
| UnionExchange | 是一个序列化算子,每个发送器向同一个目标节点发送数据,接收器union各个发送者的数据。 |
| SingleMergeExchange | 是一个分发算子,每个发送者向一个单接收器发送排序数据,接收器合并所有数据。可用于order by操作,要求最终全局有序。 |
| BroadcastExchange | 是一个分发算子,每个发送器发送数据给N个接收器,通过广播的形式。 |
| UnorderedMuxExchange | 在一个节点上所有的minor fragment的数据进行复用,使得数据通过一个单一通道就可以发送到目标接收器。一个发送节点上只要为每个接收节点维护一个缓冲区,而不是每个接收节点的每个minor fragment。 |
Join算子
| 算子 | 描述 |
|---|---|
| Hash Join | 用于内连接、左连接、右连接以及全外连接。一个hash表构建于Hash Join的inner child产生的数据,outer child的数据用于探测这个hash表并寻找匹配的。这个算子持有整个join右侧的数据集在内存中,每个minor fragment能达到20亿。 |
| Merge Join | 用于内连接、左连接、右连接以及全外连接。要求输入的数据必须排好序的,从两侧读取排序记录,寻找匹配的行。这个算子持有来自join两侧一个输入记录批次的内存。 |
| Nested Loop Join | 内嵌循环连接用于特定类型的笛卡尔连接和不等式连接。 |
聚合算子
| 算子 | 描述 |
|---|---|
| Hash Aggregate | 基于group by的key构建的hash表,hash聚合对输入数据执行分组聚合。这个算子持有每个聚合分组的内存,每个minor fragment聚合的值达到20亿个值。 |
| Streaming Aggregate | 流聚合执行分组聚合和非分组聚合。对于分组聚合,数据必须是按照分组key进行排序的。聚合的值在每个组中被计算。对于非分组聚合,数据不一定必须被排序。这个算子维护一个单一聚合分组(keys和聚合中间值),以及接入的一个记录批次大小。 |
排序和limit算子
| 算子 | 描述 |
|---|---|
| Sort | 用来执行order by操作,以及要求数据有序的上行算子操作(例如,merge join、streaming aggregate) |
| ExternalSort | 外排算子可能在内存中持有整个数据集。当内存有压力时,算子也会托管到磁盘,这种情况下,算子也会尽量使用更多的内存。在所有场景下,外部排序为每个记录溢出在内存中至少保留一个记录批次。溢出大小目前取决于外部排序算子的可用内存量。 |
| TopN | 用于执行order by + limit |
| Limit | 限制返回行数 |
投影算子
| 算子 | 描述 |
|---|---|
| Project | 投影字段或包含列和常量表达式 |
过滤和关系算子
| 算子 | 描述 |
|---|---|
| Filter | 计算WHERE或者HAVING谓词 |
| SelectionVectorRemover | 和Sort、Filter算子一起使用,此算子维护的内存量大约是单个传入批次内存量的两倍 |
集合算子
| 算子 | 描述 |
|---|---|
| Union All | 接收两个输入流,和生成一个输出流。right输入行紧跟left输入行。列名继承自left输入,left和right的字段类型必须兼容。 |
scan算子
| 算子 | 描述 |
|---|---|
| Scan | 执行底层表的扫描,格式有parquet、text、json等等。 |
接收算子
| 算子 | 描述 |
|---|---|
| UnorderedReceiver | 可容纳5个输入记录批次 |
| MergingReceiver | 这个算子为每个输入流保存5个记录批次(一般,节点数量或发送fragment的数量,取决于muxxing的使用) |
发送算子
| 算子 | 描述 |
|---|---|
| PartitionSender | 为每个outbound目标维护一个队列。outbound的minor fragment数量或者节点数量,取决于muxxing操作的使用。每个队列为每个目标最多可村3个记录批次。 |
文件写入
| 算子 | 描述 |
|---|---|
| ParquetFileWriter | 写缓冲大小大约是默认Parquet在minor fragment内存中行组大小的两倍 |