Paper翻译 Spark SQL Relational Data Processing in Spark
摘要
Spark SQL是Apache Spark中的一个新模块,用于将关系处理和Spark的函数编程API相集成。基于Shark的经验,Spark SQL使得Spark开发者能够充分利用关系处理(声明式查询和优化后的存储)的优势以及让SQL用户调用Spark中复杂的分析库(如机器学习)。与之前的系统相比,Spark SQL主要有两个优势:一是在关系型和过程处理间集成更加紧密,通过一个声明式的DataFrame API来集成过程式Spark代码。二是包含了一个高扩展性的优化器Catalyst,使用Scala编程语言特性构建,使得添加可组合的规则、控制代码生成和定义扩展点比较容易。使用Catalyst,我们已经构建了许多特性(如JSON方式的模式引用,机器学习类型以及外部数据库的联邦查询)来满足现代数据分析的复杂需求。我们认为Spark SQL是Spark上的SQL和Spark本身的一种进化,它提供了更丰富的API和优化,同时保留了Spark编程模型的优点。
关键词
数据库;数据仓库;机器学习;Spark;Hadoop
1. 引言
大数据应用要求处理技术、数据源以及存储格式的融合。早期设计的系统,是针对这些workloads,比如MapReduce,给用户提供了一个强大的、底层的、过程式编程接口。编程这样的系统是让人费力的,要求用户人工优化来获得更高的性能。因此,许多新的系统都在寻求提供一个更加有效的用户体验,通过为大数据提供一个关系型接口。比如Pig、Hive、Dremel以及Shark[29,36,25,38]这些系统,都利用了声明式查询优势来提供更加丰富的自动优化。
虽然关系型系统的流行表明用户通常更喜欢编写声明式查询,但是关系型方法对于许多大数据应用程序来说是不够的。首先,用户想从多个数据源中执行ETL,也许是半结构化或非结构化的,这要求自定义开发。其次,用户想执行高级的分析,比如机器学习和图形处理,这些在关系型系统中表达出来一个挑战。实际上,我们发现大部分数据管道可以理想地通过关系查询和复杂过程算法的组合来表达。不幸地是,这两类系统-关系型和过程型,到目前为止,它们在很大程度上仍然是分离的,迫使用户选择一种模式或另一种模式。
本论文描述了我们在Spark SQL上组合多个模型的工作与努力,作为Apache Spark[39]中一个关键的组件。Spark SQL的构建基于中早期的成果,叫做Shark。不用强制用户在关系型和过程式API中做出选择,而是在两者之间无缝混合使用。
Spark SQL通过两方面努力,架起了两种模型之间的桥梁。首先,Spark SQL提供了一个DataFrame API,可以在任何外部数据源和Spark内置分布式集合上执行关系型操作。这个API类似R[32]中被广泛使用的data frame的概念,但是会延迟计算操作,以便它可以执行关系优化。其次,为了支持大量数据源和大数据算法,Spark SQL引入了一个新式的可扩展优化器,叫做Catalyst。Catalyst可以使得Spark SQL更容易添加数据源,优化规则以及领域内数据类型,如机器学习。
DataFrame API在Spark程序中提供了丰富的关系型和过程型集成。DataFrames是一种结构化记录集合,通过Spark的过程式API或者关系型API(具备丰富的优化)来管理。它们可以通过Spark内置的分布式Java或Python对象来创建,使得在Spark程序中可以进行关系型处理。其他Spark组件,比如机器学习库,也可以获取和创建DataFrames。在许多场景下,DataFrames比起Spark的过程式API更加方便和高效。例如,可以使用一个SQL描述来计算多个阶段的聚合,而在传统的函数API方式表达就比较困难。也可以自动将数据以列式的格式存储,这个比Java或Python对象有更好的压缩。最后,不像已有的R和Python中的data frame,Spark SQL中的DataFrame操作是经过关系优化器Catalyst的。
为了在Spark SQL中支持更加广泛的数据源和分析workloads,我们设计了一个可扩展的查询优化器Catalyst。Catalyst使用Scala编程语言的特性,如模式匹配,以图灵完备语言来表达可组合的规则。提供了一个通用框架用于转换trees,并用来执行分析、计划以及运行时codegen。通过这个框架,Catalyst能够基于新数据源扩展,包含半结构化数据,比如JOSN以可以谓词下推的高效存储(如HBase);用户自定义函数或领域自定义类型,如机器学习。函数式语言适合用于构架编译器[37],所以用于很容易构建一个可扩展的优化器,并不感到惊讶。我们发现Catalyst确实能够有效地快速添加Spark SQL的能力,因为它的发布,我们已经看到很多外部开发者也很容易添加它。
Spark SQL是在2014年5月发布,现在是Spark组件中最活跃的开发组件之一。在写这篇文章的时候,Apache Spark是大数据处理中最活跃的开源,过去一年达到了400个贡献者。Spark SQL已经在很多大规模环境下部署。例如,最大的Internet公司使用Spark SQL构建数据管道,在8000个节点、超100PB数据的集群上运行查询。每个查询通常要操作数十TB数据。而且,许多用户采用Spark SQL不仅仅为了SQL查询,而是在程序中和过程式处理组合使用。例如,2/3的Databricks Cloud的客户,运行Spark的托管服务,在其他编程语言中使用Spark SQL。性能方面,我们发现Spark SQL比其他Hadoop上关系查询的纯SQL系统更有竞争力。同时,用SQL表示的计算要比原生Spark代码快10倍同时内存使用更加高效。
一般来说,我们认为Spark SQL是核心Spark API的一个重要发展。虽然,Spark传统的函数式编程API是很普遍的,但这使得自动优化的机会非常有限。Spark SQL同时使Spark可以被更多的用户访问,并改进了对现有用户的优化。在Spark中,社区正在将Spark SQL合入更多的API中,针对机器学习,DataFrames是标准的数据表现方式在新的“ML pipeline”的API中。以及我们希望扩展到其他组件中,比如GraphX和Streaming。
第二章节,我们以Spark为背景,Spark SQL为目标,开始本篇论文。然后,在第三章节描述DataFrame API,第四章节Catalyst优化器以及第五章节基于Catalyst构建的高级特性。在第六章,给出Spark SQL评测。在第七章,描述外部研究。最后,第八章节给出相关工作。
2. 背景与目标
2.1 Spark 概述
Spark是一个通用的集群计算引擎,支持Scala、Java以及Python API,以及streaming、graph处理和机器学习[6]的库。在2010年发布,是广泛使用的语言集成API系统,类似DryadLINQ[20],同时也是大数据处理中,最活跃的开源项目之一。Spark在2014就有超过400个贡献者,被多个软件供应商集成。
Spark和其他系统[20,11]类似,提供一个函数式编程API,让用户操作分布式集合,叫做弹性分布式数据集(RDDS)[39]。每个RDD就是一个夸集群的Java或Python对象分区集合。RDDS可以通过类似map、filter和reduce的操作来管理,在编程语言中使用这些函数,将会把它们分发至集群的各个节点上。例如,下面统计文本文件中ERROR打头的行数的Scala代码:
1 | lines = spark.textFile("hdfs://...") |
这段代码通过读取HDFS文件,创建RDD的lines,使用filter来转换得到另一个RDD,errors。然后在数据上执行count操作。
RDDs是一个具备容错的,可以使用RDD的血缘图来恢复丢失的数据(通过重新运行操作,比如重新执行filter来重建丢失的分区)。它们也可以显式地缓存在内存或磁盘中来支持迭代计算[39]。
RDD APIs的最后一点说明是延迟计算的。每个RDD表达了一个“逻辑计划”来计算数据集,但是Spark会等待特定的输出操作,比如count,来发起一个计算。这使得引擎可以做一些简单的查询优化,比如管道化操作。例如,在上面的例子中,Spark将从HDFS文件中管道式读取行数,应用filter和计算一个count统计,使得它不用物化中间的lines和errors结果。虽然这样的优化非常有用,但是非常有限因为引擎不理解RDD中的数据结构(任意的JAVA或Python对象)或者用户函数的语义(包含任意的代码)。
2.2 Spark上早期关系系统
我们早期在Spark构建的关系型接口是Shark[38],这个是修改了Apache Hive的系统运行在Spark上,实现了传统的RDBMS优化,比如列式处理,在Spark引擎之上。虽然Shark显示一个好的性能,以及和Spark集成的好机会,但是还是具有三个重要的挑战:
- 首先,Shark仅仅用于查询存储在Hive Catalog中的外部数据,因此对于Spark程序中的数据(比如上述手动创建的errors RDD),进行关系型查询是没有用的;
- 其次,从Spark程序调用Shark的唯一方法是将一个SQL字符串组合在一起,这在模块化程序中是不方便和容易出错的;
- 最后,Hive的优化是针对MapReduce的,很难扩展,构建一个新特性也比较困难,比如数据类型用于机器学习或支持新的数据源。
2.3 Spark SQL目标
基于Shark的体验,我们想扩展关系型处理,来覆盖Spark中的原生RDD以及更广泛的数据源。目标如下:
- 在Spark程序中支持关系型处理(在原生RDD上),以及在外部数据源上使用开发者友好的API;
- 使用成熟的DBMS技术来提供更高的性能;
- 更加容易地支持新的数据源,包含半结构化数据和外部数据库,满足联邦查询;
- 支持高级分析算法扩展,比如图计算和机器学习。
3. 编程接口
Spark SQL作为一个库运行在Spark之上,如图1所示。表示SQL接口可以通过JDBC/ODBC或者命令行控制台访问,也可以通过集成到Spark中,来支持编程语言的DataFrame API,让用户可以混合使用过程式和关系型代码。然而,高级函数也可以通过UDFs在SQL中表示,通过BI工具调用。这个我们将在3.7章节讨论。
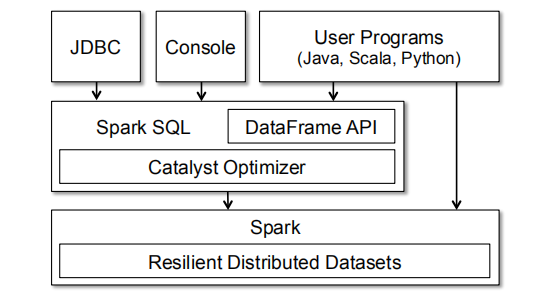
3.1 DataFrame API
在Spark SQL的API中最主要抽象就是DataFrame,即带有同样schema的rows分布式集合。一个DataFrame等价于关系型数据库中的一个表,也可以通过类似Spark中原生分布式集合RDD的方式来处理。与RDD不同,DataFrames含有数据的schema,以及支持各种关系型操作能够得到进一步地优化执行。
DataFrames可以通过系统catalog中的表(外部数据源)或者已有的原生Java/Python对象RDD(3.5章节)来构建。一旦构建成功,就可以使用各种关系型操作,比如where和groupBy,可以接受DSL中的各种表达式,类似R语言和Python中[32, 30]的data frames。每个DataFrame也可以被视为是一个Row对象的RDD,允许用户调用过程式Spark API,比如map。
最后,与传统的data frames的API不同,Spark的DataFrames式懒加载的,在每个DataFrame对象中,都表示一个逻辑计划来计算dataset,但不会执行直到用户调用的特定的输出操作,比如save。这使得可以跨越所有操作的丰富优化,能够使用在DataFrame的构建中。
为了说明这一点,如下的Scala代码从一个Hive表中定义了一个DataFrame,基于它获得了另外一个DataFrame,并打印结果:
1 | ctx = new HiveContext() |
在这段代码中,users和young是DataFrames。users("age") < 21的代码片段是data frame DSL中的一个表达式,作为一个抽象语法树,而不是代表传统Spark API的Scala函数。最后,每个DataFrame都代表了一个逻辑表达式(比如,读取users表和过滤age < 21)。当用户调用count时,是一个输出操作,Spark SQL会构建一个物理表达式来计算最终的结果。这也许会包含一个游湖,比如仅仅scan数据的age列,假如它的存储是列式的,或者使用数据源中索引来统计匹配的行。
3.2 数据模型
对于表和DataFrames,Spark SQL使用基于Hive[19]的内嵌数据模型。支持所有主要的SQL数据类型,包含boolean、integer、double、decimal、string、date和timestamp以及复杂的数据类型(非原子的):structs、arrays、maps和unions。复杂的数据类型也可以嵌套在一起,来创建一个更强大的类型。与许多传统的DBMS不同,Spark SQL为查询语言和API中的复杂数据类型提供一流的支持。而且,Spark SQL也支持用户自定义类型,这个在4.4.2章节说明。
使用这个类型系统,我们能够准确地模型化来自各种数据源和文件格式的数据,包括Hive、关系型数据库、JSON以及Java/Scala/Python的原生对象。
3.3 DataFrame操作
用户能够在DataFrames中使用DSL来执行关系型操作,类似R语言中的data frames[32]和Python中的Pandas[30]。DataFrames支持所有的通用关系型操作(算子),包括projection(select),filter(where),join和aggregations(groupBy)。这些算子在有限的DSL中都可以表达出来,是的Spark能够获取表达式的结构。例如,如下的代码,计算每个部门的女雇员的数量:
1 | employees |
这里,employees是一个DataFrame,employees(“deptid”)是一个表示deptId列的表达式。表达式对象有许多操作能够返回一个新的表达式,包含常用的比较操作符(例如,=== 等值判断,> 大于)以及数学操作(+,- 等)。所有这些操作都构建在一个表达式的抽象语法树AST上,然后传递给Catalyst进行优化。与原生Spark API中使用函数包含任意Scala/Java/Python代码不同,这些代码对于runtime引擎来说是不透明的。针对详细的API列表,我们可以参考阅读Spark的官方文档[6]。
除了关系型DSL,DataFrames可以被注册为一个系统catalog中的临时表,然后使用SQL来查询。如下代表给出了示例:
1 | users.where(users("age" < 21)).registerTempTabel("young") |
SQL有时候用于简单计算多个聚合是非常方便的,也允许程序通过JDBC/ODBC的方式暴露datasets。在catalog中注册的DataFrames,还是一个未物化的食物,使得优化操作可以发生在SQL和原始DataFrame表达式中。但是,DataFrames也是可以被物化的,这个在3.6章节讨论。
3.4 DataFrames和关系型查询语言对比
虽然,表面上DataFrames提供了类似关系型查询语言的同样的操作,如SQL和Pig[29],但是我们发现让用户更容易地使用,多亏了他们在整个编程语言中的集成。例如,用户能够把他们的代码拆解为Scala,Java或Python函数,在他们之间传递DataFrames来构建逻辑计划,同时还可以在运行输出操作时在整个计划上执行优化。同样,开发人员可以使用控制结构(如if语句和循环)来构造工作。一位用户说,DataFrame API“像SQL一样简洁、声明性强,但我可以命名中间结果”,指的是如何更容易构造计算和调试中间步骤。
为了更加简化DataFrames中的编程,我们使得API可以尽早地分析逻辑计划(比如,识别表达式中的列名是否在底层表中,以及它们的数据类型是否正确),即使查询结果是延迟计算的。因此,只要用户输入一个无效代码行,Spark SQL就会报告一个错误,而不是等到执行时,这比起一个大SQL同样容易使用。
3.5 查询原生Datasets
实际场景的数据pipelines是从异构数据源中抽取数据,运行来自不同程序库的各种算法。为了和过程式Spark代码交互,Spark SQL允许用户基于原生RDD对象直接构建DataFrames。Spark SQL可以自动使用发射来获取这些对象的schema。在Scala和Java中,类型信息可以从语言类型系统中抽取(JavaBeans和Scala Case类)。在Python中,由于动态类型系统,Spark SQL对dataset进行采样以执行模式推断。
例如,如下Scala代码从一个User对象RDD定义了一个DataFrame。Spark SQL自动检测列的名称(name和age)和数据类型(string和int)。
1 | case class User(name:String, age:Int) |
内部,Spark SQL创建一个逻辑数据scan操作,指向RDD。这个被编译为物理操作,访问原生对象的字段。这个完全不同于传统的ORM。ORM一般会出现昂贵的转换操作,将整个对象翻译为不同格式的对象。相反,Spark SQL访问原生对象,仅仅提取每个查询中使用的列。
查询原生dataset的能力可以让用户运行优化后的关系操作,在已有的Spark程序中。而且,将RDD和外部结构化整合更加简单。例如,我们将users RDD和Hive表进行Join操作:
1 | views = ctx.table("pageviews") |
3.6 内存缓存
和之前的Shark一样,Spark SQL可以使用列存储将热数据物化(通常称为“缓存”)。与Spark原生cache相比(简单地存储数据为JVM对象),列缓存可以将内存占用减少一个数量级,因为可以应用列式压缩机制,如字典编码和行程编码。缓存对于交互查询和机器学习的迭代算法是非常有用的。可以通过DataFrame的cache()方法来调用。
3.7 用户自定义函数
用户自定义函数(UDF)是数据库系统很重要的扩展。例如,MySQL依赖UDF提供JSON数据的基本支持。更高级的例子,MADLib使用UDF为Postgres和其他数据库系统[12]实现机器学习算法。然而,数据库系统要求UDF在一个独立编程环境下定义,不同于基础的查询接口。Spark SQL的DataFrame API支持内联UDF的定义,不需要复杂的打包以及注册流程。事实证明,这个特性对于API的采用至关重要。
在Spark SQL中,能够通过Scala、Java或Python函数来内联注册UDF,这些函数可以在内部完整地使用Spark API。例如,给定一个机器学习模型的model对象,我们可以将预测函数注册为UDF:
1 | val model : LogisticRegreesionModel = ... |
一旦注册,BI工具就可以通过JDBC/ODBC接口来使用这个UDF。除了对标量值进行操作的UDF(如本文所示)之外,还可以定义对整个表进行操作的UDF,如MADLib[12]中所示,并在其中使用分布式Spark API,从而公开高级的
SQL用户的分析功能。最后,由于UDF定义和查询执行是使用相同的通用语言(例如Scala或Python)表示的,所以用户可以使用标准工具调试或分析整个程序。
上面的示例演示了许多pipelines中的一个常见用例,即同时使用关系型运算符和高级分析方法的用例,这些方法在SQL中是难以表达的。DataFrame API允许开发人员无缝地混合这些方法。
4. Catalyst优化器
为了实现Spark SQL,我们设计了一个新的可扩展优化器Catalyst,基于Scala的函数式编程构建。Catalyst的可扩展设计有两个目的:一是,在Spark SQL中更加容易地添加新的优化技术和特性,尤其是在大数据中要解决遇到的各种问题(比如,半结构化数据和高级分析)。二是,让外部开发者能够扩展优化器,例如通过加入数据源的特定规则,能够将过滤或聚合下推到外部存储系统中,或者支持新的数据类型。Catalyst对RBO和CBO都支持。
虽然,可扩展优化器在过去已经被提出,但一般要求比较复杂的DSL来指定规则,和一个优化器编译器来将规则翻译为可执行代码[17, 16]。这将导致一个很重的学习曲线和维护负担。相反,Catalyst使用Scala函数式编程的标准特性,比如模式匹配[14],让开发人员使用完整的编程语言,同时使规则易于指定。函数式语言的设计部分是为了构建编译器,所以我们发现Scala非常适合这个任务。然而,据我们所知,Catalyst是第一个基于这种语言构建的生产级质量的查询优化器。
在核心代码中,Catalyst包含了一个通用的库,用于表示trees,和应用rules来看你管理trees。在这个框架之上,针对关系查询处理,我们已经建了许多的库(比如expressions、逻辑查询计划),以及都许多规则用于处理查询执行的不同阶段,包括分析、逻辑优化、物理计划以及codegen来将部分查询编译为Java字节码。针对最后一个,我们使用了另外一个Scala特性,quasiquotes[34],使得运行时从可组合的表达式生成代码更加容易。最后,Catalyst提供了许多扩展点,包括外部数据与啊以及用户自定义类型。
4.1 Trees
在Catalyst中最重要的数据类型就是由多个node对象构成的tree。每个node有一个类型、0或多个子节点。新的node类型通过Scala定义,作为一个TreeNode的子类。这些对象是不可变的,可以通过函数式转换来控制,这个在后续章节讨论。
正如下面的例子,假设针对一个简单的表达式语言,我们有三个node类:
- Literal(value: Int): 一个常量值;
- Attribute(name: String): 一个输入row的属性,例如,”x”;
- Add(left: TreeNode, right: TreeNode): 两个表达式求和。
这些类用来构建tree,例如,表达式x+(1+2),如图2所示,将通过如下Scala代码表示:
1 | Add(Attribute(x), Add(Literal(1), Literal(2))) |

4.2 Rules
Trees是可以通过Rules来控制的,规则一中可以将一个tree转化为另一个tree的functions。虽然一个规则在输入的tree上(假定tree就是一个Scala对象)可以执行任意代码,但大部分方式是通过一个模式匹配functions集合,来检索和使用特定的结构来替换子树。
模式匹配是许多函数式语言的一个特性,可以从关系代数数据类型的内嵌结构中抽取相关的信息。在Catalyst中,trees提供了一个transform的方法,可以在tree的所有节点上递归应用模式匹配函数,将每个符合模式的节点tranform成一个结果。例如,我们可以实现一个规则,折叠常量的Add操作,如下:
1 | tree.transform { |
将这个规则,应用在x+(1+2)的树上,在图2中,合并成一个新的tree为x+3。case关键词是Scala中标准模式匹配的语法[14],可以用来匹配一个对象的类型,以及根据给定的名称来抽取值(如c1和c2)。
这个传递给transform的模式匹配表达式是一个partial function(偏序函数),意味着它只需要匹配所有可能的输入树的子集。Catalyst将测试给定规则适用于树的哪些部分,自动跳过并降序到不匹配的子树中。这个能力使得规则只需要应用在给定优化的树,没有匹配的部分不用考虑。因此,rules不需要被修改为算子的新类型,加入到系统中。
在同样的transform调用中,rules(以及Scala的模式匹配)能够匹配多个模式,使得它可以同时实现多个transformations:
1 | tree.transform { |
实际上,rules也许需要执行多次才能完全transform一个tree。Catalyst将rules分组为batches,执行每个batch直到达到一个固定点,也就是在应用这些规则之后,直到tree停止改变。将规则运行到固定点意味着每个规则都可以是简单和自包含的,但最终仍然会对树产生更大的全局影响。在上述示例中,重复应用规则将会常量折叠一个更大的trees,比如(x+0)+(3+3)。在另一个例子中,第一个batch也会分析一个表达式,给所有attributes分配类型,而第二个batch也许会使用这些类型进行常量折叠。在每个batch处理之后,开发人员还可以对new tree运行健全性检查(例如,查看所有属性是否都被分配了类型),通常也是通过递归匹配来编写的。
最后,rule的条件和它们的内部包含任意Scala代码。这使得Catalyst比起DSL在优化器方面更加强大,同时保持了简单规则的简洁性。
在我们的经验中,在可变trees上的函数式transformations使得整个优化器更加容易推理和调试。还可以做到在优化器中实现并行化,虽然我们还没有使用到它。
4.3 在SparkSQL中使用Catalyst
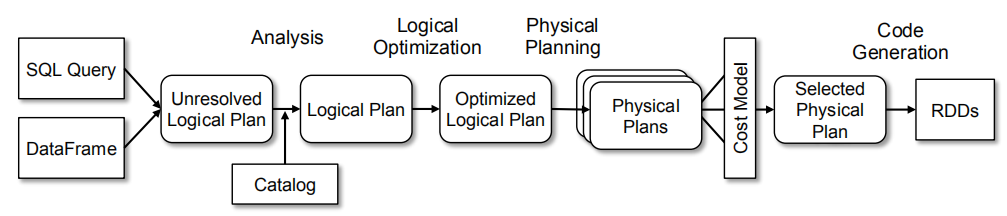
我们在4个阶段使用Catalyst的通用tree transformation框架,如图3所示:
- 分析逻辑计划来解析引用;
- 逻辑计划优化;
- 物理计划;
- 代码生成,将查询部分逻辑编译为Java字节码。
在物理计划阶段,Catalyst也会生成多个计划,然后基于代价进行比较,其他所有阶段都是基于规则的。每个阶段使用不同类型的tree nodes;Catalyst包含了表达式、数据类型、逻辑和物理算子的。node库。
4.3.1 分析
Spark SQL从一个SQLParser返回的AST或者使用API创建DataFrame对象开始关系计算。在这两个场景中,这个关系包含了unresovled的attribute引用或者关系:例如,在SQL查询SELECT col FROM sales中,col的类型或者列名是否有效都是未知的直到我们找到表sales。如果我们不知道它的类型或者还没有匹配到一个输入的表(或者别名),那么attribute就被视为unresovled。Spark SQL使用Catalyst的rule和一个Catalog对象,在所有数据源上跟踪这个表来resolve这些attributes。首先,构建一个带有未绑定的attributes和数据类型的unresolved逻辑计划,然后按照如下流程应用rules:
- 从catalog中,通过name查找relations;
- 将命名了的attributes映射为输入提供给指定算子的children;
- 决定哪些attributes引用同一个值,给它们一个unique ID(之后可以优化表达式,比如col = col);
- 通过表达式,传播和强制类型:例如,我们不知道1 + col的类型,直到resolved了col和可能将子表达式转为兼容的类型。
总之,分析器的rule大概有1000行代码。
4.3.2 逻辑优化
逻辑优化阶段,将应用标准的基于规则的优化操作在逻辑计划上。这些包含了常量折叠、谓词下推、投影剪枝、null传播、布尔表达式简化以及其他rules。通常,我们发现针对各种场景,我们添加一些规则是非常简单的。例如,当我们在Spark SQL中,添加一个固定精度的DECIMAL类型时,我们想优化聚合操作,如在小精度的DECIMAL上的sums和averages操作;大概要12行代码来写一个规则,在SUM和AVG表达式中寻找decimals,之后把它们cast为一个unscaled 64位long,做完聚合计算后,再把结果转换回去。改规则的一个简单的版本,仅仅用于优化SUM表达式,如下再表示一下:
1 | object DecimalAggregates extends Rule[LogicalPlan] { |
另外一个例子,一个12行代码的规则,将带有一个简单的正则表达式的LIKE表达式优化为一个String.startWith或者String.contains的调用。在rule中可以自由使用任意Scala代码,来实现这些优化,它超越了模式匹配的子树结构,易于表达。
总之,逻辑优化的rule有800行代码。
4.3.3 物理计划
在物理计划阶段,Spark SQL使用逻辑计划,生成一个或多个物理计划,使用能够匹配Spark执行引擎的物理算子。使用代价模型来选择一个计划。当前,基于代价的优化器仅仅用于选择JOIN算法:针对一个较小的relations,Spark SQL会使用broadcast join,使用Spark中点对点广播的能力。然而,该框架支持更广泛地使用基于代价的优化,因为可以使用规则可以递归地估算整个tree的代价。在未来,我们打算实现更加丰富的基于代价的优化。
物理planner也可以执行基于规则的物理优化,比如将投影或过滤操作pipelining到Spark的map操作中。而且,可以将逻辑计划中的操作下推到支持谓词或投影下推的数据源中。我们将在4.4.1章节描述这些数据源的API。
总之,物理计划的rule大概有500行代码。
4.3.4 代码生成
查询优化的最后一个阶段,涉及到生成Java字节码,运行在每个机器上。因为,Spark SQL经常在内存的Datasets上执行操作,处理是受限于CPU的,因此我们想支持codegen来加速执行。尽管如此,codegen引擎通常很难构建,实质上相当于一个编译器。Catalyst基于Scala语言的特殊特性,quasiquotes[34],使得codegen变得容更加简单。Quasiqutoes允许在Scala语言中以编程方式构造抽象语法树(AST),然后可以在运行时将其提供给Scala编译器以生成字节码。我们使用Catalyst将SQL中tree表达式转换为Scala代码的AST,来计算这个表达式,之后编译和运行生成的代码。
正如章节4.2中介绍的例子,Add、Attribute以及Literal的tree node,可以用来编写一个表达式(x+y)+1。如果没有codegen,这个表达式将针对每行数据,向下遍历tree中的Add、Attribute和Literal节点。这将会引入大量的分析和虚函数的调用,降低执行的性能。通过codegen,我们能够编写一个函数,将特定的expression tree翻译为Scala AST,如下所示:
1 | def compile(node:Node): AST = node match { |
以q开头的字符串就是quasiquotes,虽然它们看起来像一个普通的字符串,实际上是可以通过Scala Compiler解析的,来表示内部代码的AST。Quasiquotes可以使用变量或者其他AST‘s的片段,通过$来表示。例如,Literal(1)转为Scala的AST为1,而Attribute(“x”)转为row.get(“x”)。最后,类似Add(Literal(1), Attribute(“x”))的tree,转为Scala代码的AST为1+row.get(“x”)。
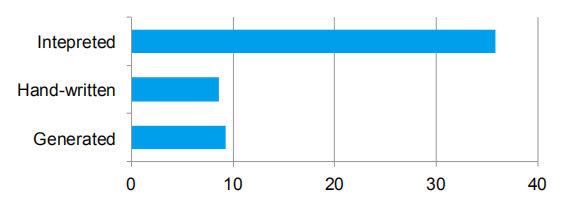
Quasiquotes在编译时进行类型检测,以确保仅有正确的ASTs或者literal被替换,这个比起字符串拼接更有使用意义,它们将直接生成Scala AST,而不是在运行执行Scala解析器。而且,它们是高度可组装的,因为针对每个node的codegen规则并不需要知道它的孩子nodes是如何构建返回的。最后,生成的code会进一步通过Scala编译器来优化,以防Catalyst错过表达式级优化。图4展示了,quasiquotes生成的代码性能和手动调整的程序性能类似。
我们发现,quasiquotes在codegen方面使用非常直接,许多新的Spark SQL contributors能够快速地为新的表达式类型添加规则。Quasiquotes也可以和原生Java对象一起使用:当从这些对象中访问fields时,我们能够直接通过codegen来访问需要的field,而不是将对象拷贝到Spark SQL Row中并使用Row的accessor方法。最后,也可以直接组合codegen计算和interpreted计算(还不能生成codegen的表达式),因为我们编译的Scala代码可以直接调用表达式interpreter(解释器)。
总之,Catalyst的code生成器大概有700行代码。
4.4 扩展点
Catalyst的设计围绕可组装的rules,使得它更容易被用户和第三方库扩展。开发者们可以添加一批rules到运行时查询优化的每个阶段,只要它们遵循每个阶段的约定(例如,保证分析阶段可以解析所有attributes)。然而,为了在不用理解Catalyst rules情况下,添加一些扩展类型更加简单,我们需要定义两个较小的公共扩展点:数据源和用户自定义类型。这些还需要依赖core引擎的基础设施和优化器的其余部分进行交互。
4.4.1 数据源
开发者们为Spark SQL开发一个新的数据源,可以使用许多API,这些API提供了各种程度的优化。所有数据源必须实现一个带有kv参数集合的createRelation函数,和返回一个BaseRelatoin对象,仅当relation的可以成功加载。每个BaseRelation包含一个schema和一个可选的计算字节大小。例如,一个表示MySQL的数据源,带有一个表名作为一个参数,向MySQL查询表大小的估计值。
为了能让Spark SQL读取数据,一个BaseRelation需要实现众多接口中的一个,这些接口允许它们公开不同程度的复杂性。最简单的是TableScan,要求relation返回一个Row对象(表中的数据)的RDD。另外一个更高级的是PrundedScan(带有列名数组),返回的Rows仅仅包含这些列。第三个接口,PrunedFilteredScan(带有需访问的列名和过滤对象数组),它是Catalyst表达式语法的子集,可以进行谓词下推。过滤器是建议性的,即数据源应该尝试返回符合过滤条件的rows,但是如果过滤器不能被计算,则需要返回false。最后一个接口是CatalystScan(带有完整地Catalyst表达式trees集合),用于谓词下推。
这些接口,使得数据源可以实现各种程度的优化,同时也使开发人员能够方便地添加几乎任何类型的简单数据源。我们以及其他人已经使用这个接口实现了如下数据源:
- CSV文件,简单地scan整个文件,用户可以指定schema;
- Avro[4],一个用于嵌套数据的自描述二进制格式;
- Parquet[5],一个列式文件格式,支持列剪枝和过滤;
- JDBC数据源,从RDBMS中并行scan一个表的范围,同时下推filters到RDBMS以最小化通信。
为了使用这些数据源,程序员们在SQL语句中指定它们的包名,配置选项通过KV对传递。例如,使用Avro数据源,持有一个指向文件的path:
1 | CREATE TEMPORARY TABLE messages |
所有的数据源还会抛出网络本地性的信息,即数据的每个分区从哪个机器上读取是最高效的。这个是通过返回的RDD对象抛出的,RDDs有一个内置的API,用于数据本地性(data locality)[39]。
最后,也有类似的接口用于写数据到已有的或者新的表中。这些更加简单,因为Spark SQL仅仅提供了一个Row objects的RDD来写。
4.4.2 用户自定义类型(UDTs)
可以在Spark SQL执行高级分析的一个特性就是用户自定义类型。例如,机器学习应用需要的vector类型,图算法需要的用于表示graph的类型,这些可能已经超出了关系型表[15]。虽然,添加一个新的类型非常有挑战,但数据类型遍及执行引擎的方方面面。例如,Spark SQL中,内置的数据类型以列式的、压缩格式存储在内存cache中(3.6章节),从之前章节的数据源API可以看到,我们需要暴露所有可能的数据类型给数据源拥有者。
在Catalyst中,我们通过将用户自定义类型映射到Catalyst内置类型(3.2章节)组合结构,来解决这个问题。为了注册一个Scala类型为UDT,用户提供一个映射关系,从它们的class对象到一个内置类型的Catalyst Row,以及一个反向转换。在用户code中,它们能够在Spark SQL查询的对象中使用Scala类型,它将会被转为底层的内置类型。同样,它们可以注册直接对其类型进行操作的UDFs(见第3.7节)。
根据一个小示例,假设我们想注册一个两维的点(x, y)作为一个UDT。我们可以通过两个double值表示这个向量。为了注册这个UDT,我们写了如下内容:
1 | class PointUDT extends UserDefinedType[Point] { |
注册完这个类型之后,在Spark SQL中访问并转为DataFrames时,Points将会原生对象中被识别,并传递给在Points上定义的UDFs。而且,Spark SQL将会以列式格式存储Points,当缓存数据时(将x和y作为单独列压缩),Points也是可以被写入到所有的Spark SQL的数据源中,以double值对的形式。在Spark机器学习库中,我们也使用了这样的能力,在5.2章节进行描述。
5. 高级分析特性
本章我们将描述在Spark SQL中加入的三大特性来解决大数据环境下的挑战。
- 第一,在大数据环境下,经常出现非结构化或半结构化数据。虽然按程序解析这些数据是可能的,但这会导致冗长的样板代码。为了让用户立刻查询数据,Spark SQL包含了一个模式推理算法,针对JSON以及其他半结构化数据。
- 第二,大规模处理往往超出了聚合,需要在数据上加入机器学习。我们描述了Spark SQL是如何被整合到Spark机器学习库的一个新的高级API中的。
- 第三,数据管道data pipelines经常需要从不同存储系统中整合数据。基于在4.4.1章节中的数据源API的构建,Spark SQL支持查询联邦,允许一个单一程序高效地读取不同数据源。
以上特性,都是基于Catalyst框架构建。
5.1 半结构化数据schema推理
在大规模环境下半结构化数据很普遍,因为随着时间的推移,很容易生成和添加字段。在Spark用户当中,我们发现JSON作为输入数据的使用率很高。不幸地是,在Spark或MapReduce这样的过程式环境中使用JSON很麻烦:大部分用户使用类ORM的库(如Jackson[21]),将JSON结构映射为Java对象,或者采用一些更低级别的库来尝试解析每个输入的记录。
在Spark SQL中,我们添加了一个JSON数据源,来自动从一个记录集合中,推断出一个schema。例如,给定JSON对象如图5所示,这个库推断出的schema如图6所示。
1 | { |
1 | text STRING NOT NULL, |
用户可以很简单地注册一个JSON文件作为一张表,通过path访问字段的语法来查询它,如下:
1 | SELECT loc.lat, loc.long |
//部分省略…
5.2 和机器学习库进行集成
作为一个Spark SQL能力在其他Spark模块中使用的例子,机器学习lib,引入了一个新的使用DataFrame[26]的high-level API。这个新的API,基于机器学习pipeline的概念,它是一种抽象,类似其他high-level机器学习库Scikit-Learn[33]。一个pipeline就是在数据上进行各种transformations的graph,比如特征提取、归一化、降维以及模型训练,每一个操作都要交换数据集。Pipelines是一个非常有用的抽象,因为机器学习工作流有许多的步骤,把这些步骤表示成可组成的各个元素,使得它更加容易改变pipeline的部分或者检索调优参数,在整个工作流的层面上。
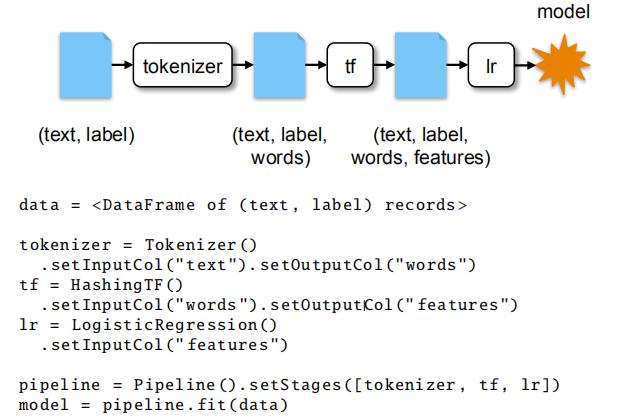
为了在pipeline stages之间交换数据,MLlib的开发者需要一个格式,可以压缩(因为数据集很大)还需具备灵活性,每条记录中可以有多种类型字段。例如,一个用户开始处理的记录,包含文本字段以及数值字段,运行特征算法后如TF-IDF,文本字段转为了一个向量vector,规范化另一个字段,对整个特征集进行降维操作等等。为了表示这个数据集,使用DataFrames的新API,每列表示数据的一个特征。在pipelines中,所有算法都可以使用,给出输入列的名字和输出列,因此可以对字段的任何子集进行调用并生成新的。这使得开发者更加容易构建复杂pipelines,同时保留每条记录的原始数据。为了说明这个API,图7给出了一个简短的pipeline和创建DataFrames的schema。从text字段提取words,运行词频统计特征器,转为特征向量,进行逻辑回归训练。
MLlib中使用Spark SQL的主要方面是为了创建自定义类型向量vectors。vector的可以存储稀疏和稠密vectors,使用四个基本类型字段表示:
- 一个是boolean类型,表示是稀疏还是稠密;
- 一个是向量的大小;
- 一个是indices数组(针对稀疏坐标);
- 一个是double值数组(针对稀疏向量的非0坐标或者所有坐标)。
除了DataFrame可以跟踪和管理columns的能力,其他实用性的原因为:在Spark支持的编程中,更加容易抛出MLlib的新API。之前,MLlib中的每个算法持有的对象,都是针对特定领域的概念的(比如,打标点分类,用户产品推荐等级),这些类必须使用各种语言实现一遍(比如,从Scala拷贝到Python)。在所有语言中使用DataFrame,可以更加简单地抛出所有算法,因为我们仅仅需要Spark SQL中的数据约定。这个在Spark绑定其他语言非常重要。
最后,在MLlib中使用DataFrame作为存储,也会更加容易使用SQL中的所有算法。我们简单定义一个在3.7章节提到的MADlib-sytle的UDFs,在表上内部调用这些算法。我们也在探索API,在SQL中构建机器学习pipeline。
5.3 外部数据联邦查询
数据pipelines通常需要整合来自异构数据源的数据。例如,推荐系统的pipeline,需要整合traffic logs和一个user profile数据库以及用户社交媒体流。这些数据源通常处在不同的机器或地理位置,查询它们可能代价很高。Spark SQL数据源任何时候,尽可能利用Catalyst进行下推谓词到数据源中。
例如,下面的例子,使用JDBC数据源和JSON数据源,join两张表,找到最近注册用户的traffic log。方便的是,所有数据源能够自动推断schema不需要用户定义。这个JDBC数据源将下推filter谓词到MySQL,来减少传输数据的数量。
1 | CREATE TEMPORARY TABLE users USING jdbc |
未来,Spark SQL的发布,我们也会为KV存储添加谓词下推的能力,比如HBase和Cassandra,它们在谓词过滤的形式有限。
6. 评估
我们从两个维度评估Spark SQL的性能:SQL查询处理性能和Spark程序性能。特别地,我们将介绍Spark SQL的可扩展性架构,不仅支持丰富的功能,而且还带来持续的性能优化,相比之前基于Spark的SQL引擎。而且,对于Spark应用开发者,DataFrame API的比起原生Spark API具有持续的加速,虽然Spark程序更加具体容易理解。最后,整合了关系型和过程式查询的应用,在集成的Spark SQL引擎上,执行的速度比起单独运行SQL和过程式代码更加快速。
6.1 SQL性能
我们将Spark SQL和Shark、Impala[23]进行性能比较,基于AMPLab的大数据benchmark[3],使用Pavlo等人[31]开发的web分析workload。这个负载包含了四种类型的查询带有不同的参数,执行scans、agg、joins以及UDFs的MapReduce作业。我们使用6个EC2 i2.xlarge机器组成的集群(1个master,5个workers),每个机器4core、30Gmem和800GSSD,运行HDFS 2.4,Spark1.3,Shark 0.9.1以及Impala 2.1.1。这个数据集是110GB的数据,是经过列式存储Parquet格式压缩后的。
图8展示了每个查询的结果,通过查询的类型来分组。查询1-3有不同的参数,它们的选择性不同,1a、2a等是最有选择性的,1c、2c等是选择性最低的,并且处理更多的数据。查询4使用基于Python的Hive UDF,在Impala中不能直接支持,很大程度受限于UDF的CPU代价。
在所有查询中,我们看到,Spark SQL一直都比Shark快,和Impala相当。和Shark的主要差异在于Catalyst中的代码生成(4.3.4章节),减少了CPU的开销。这个特性使得Spark SQL与基于C++和LLVM的Impala引擎具有的一定竞争性。在查询3a中和Impala最大的差距就是,Impala选取了一个更好的join计划,因为查询的选择性使得其中一个表很小。

6.2 DataFrames对比原生Spark Code
除了运行SQL查询,Spark SQL也能让非SQL开发者写一个更加简单、更加高效Spark Code,通过DataFrame的API。Catalyst可以在DataFrame的操作上执行优化,这个硬编码很难做到的,比如谓词下推、pipelining以及自动join的选择。甚至如果没有这些优化,DataFrame的API也能够做出更加高效地执行,由于codegen的作用。这个对于Python应用也是一样的,因为Python一般是比JVM慢的。
针对这个计算,我们比较了Spark程序的两种实现,做一个分布式的聚合。数据集由10亿的整形对(a, b构成,其中a有10万个唯一值,在同样的5个worker i2.xlarge集群上。我们计算了每个a值对应的b值的平均值,我们衡量这个耗时。首先,我们看一个版本,就是使用Spark的Python API中的map和reduce函数来计算平均值:
1 | sum_and_count = |
相反,使用DataFrame API的,只需要如下简单的管理:
1 | df.groupBy("a").avg("b") |
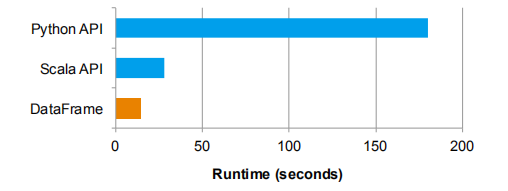
图9显示了DataFrame版本的代码性能是Python版本的12倍,而且更加简洁。这是因为DataFrame API,仅仅逻辑计划是通过Python构建的,所有的物理执行都被编译为原生Spark代码作为JVM字节码,会得到一个更加高效的执行。实际上,DataFrame版本也比Scala版本的代码性能高出2倍。主要由于codegen:DataFrame的代码版本避免了手写Scala代码中,昂贵的KV对空间申请。
6.3 Pipeline性能
DataFrame的API也能够在应用中优化性能,通过整合关系型和过程式处理,让开发者将所有的操作写在一个单独的程序中,跨越关系型和过程式代码,形成流水线计算。举个简单的例子,我们考虑一个2阶段的pipeline,从语料库中选择文本消息的子集并计算最常用的单词。虽然很简单,但是能对一些真实世界的pipelines建立模型。例如,计算特定人群在tweet中使用的最流行词汇。
在这个实验中,我们在HDFS中生成了一个包含100亿条消息的合成数据集。每条信息平均包含10个从英语词典中提取的单词。pipeline的第一个阶段就是使用关系型过滤,来初略选择90%的数据,第二阶段就是计算单词数据量。
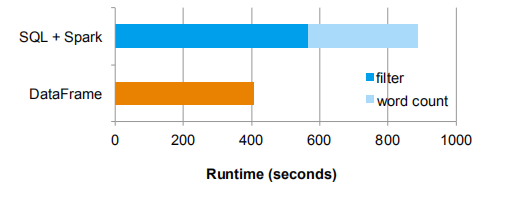
首先,我们使用一个单独的SQL查询和一个基于Scala的Spark作业来实现管道,这可能发生在运行单独的关系引擎和过程引擎的环境中(例如,Hive和Spark)。然后,我们又实现一个组合的管道,使用DataFrame的关系算子执行过滤,使用RDD的API在结果上执行单词统计。与第一个pipeline相比,第二个pipeline避免了在传递给Spark作业之前,将整个SQL查询结果的保存到HDFS作为中间结果集的成本。因为,Spark SQL将用于单词统计的map操作和用于过滤的关系算子进行管道化操作。图10给出了两种方法的运行性能比较,除了更加容易理解和操作之外,基于DataFrame的pipeline性能也提升2倍。
7. 研究应用
7.1 通用在线聚合
//省略…
7.2 基因学计算
//省略…
8. 相关工作
8.1 编程模型
许多系统试图将过程式处理和关系型处理相结合,使用在大规模集群中。Shark[38]是最接近于Spark SQL的,运行在相同的引擎之上,提供同样的关系型查询和高级分析的结合。Spark SQL通过一个丰富的和对开发者更加友好的API,DataFrames,对Shark进行了改进。在宿主编程语言中构造的查询,可以以模块化的方式组合在一起(见3.4章节)。也可以在原生RDDs上直接运行关系型查询,支持除Hive以外的更多数据源。
给Spark SQL的设计带来灵感的系统是DryadLINQ[20],它是在C#中将语言集成查询编译为分布式DAG执行引擎。LINQ查询也是关系型的,但是能够直接对C#对象进行操作。Spark SQL超越了DryadLINQ,提供一个类似公共数据科学库[32, 30]的DataFrame接口,作为数据源和类型的API,支持在Spark上执行的迭代算法。
其他一些系统只在内部使用数据模型,将过程式代码转为UDFs。例如,Hive和Pig[36, 29]提供关系型查询语言,但是大量使用UDF接口。ASTERIX[8]内部有一个半结构化数据模型。Stratosphere[2]也有一个半结构化模型,但是提供了Scala和Java的API,让用户很容易使用UDFs。PIQL[7]也同样提供了Scala的DSL。与这些系统相比,Spark SQL和原生Spark应用集成更加紧密,能够直接在用户自定义类中查询数据(原生Java/Python对象),让开发者在同一个语言环境下,混合使用过程式和关系型APIs。而且,通过Catalyst优化,Spark SQL实现了优化(例如Codegen)和其他功能(流入JSON和机器学习数据类型的模式推断),这些在大规模计算框架中是没有的。我们相信这些特性从本质上为大数据提供了一个集成的,易于使用的环境。
最后,DataFrame API既可以在单个机器[32, 30]也可以在集群[13, 10]上构建。不像之前的APIs,Spark SQL通过关系优化器,优化了DataFrame的计算。
8.2 扩展的优化器
Catalyst优化器与可扩展优化器框架,如EXODUS[17]和Cascades[16]有着相似的目标。虽然,传统上优化器框架要求一个DSL来写规则,同时一个优化器的编译器,将它们翻译为可运行的代码。我们的主要改进就是采用一个函数式编程语言来构建我们的优化器,提供了同样或更好的表达性,同时降低了维护成本和学习曲线。高级语言特性在Catalyst的方方面面有所帮助,例如,CodeGen采用quasiquotes(4.3.4章节所述)的方式,是这项任务中最简单、最易组合的方法之一。虽然,扩展性很难衡量质量,但有一个有希望的迹象是,Spark SQL在发布后的头8个月内有超过50个外部贡献者。
针对CodeGen,LegoBase[22]最进提出一个方法,使用Scala中的生成式编程,有可能是替代quasiquotes。
8.3 高级分析
Spark SQL近期的工作主要是在大规模集群中运行高级分析算法,包括平台迭代算法[39]和图分析[15, 24]。
9. 总结
//省略…
10. 致谢
//省略…
11. 参考文献
//待完善…