极客邦连麦百位牛人观后实录
从书上学·在事中练·与高人聊!心力!
极客邦访谈100位牛人,通过直播方式为程序员提供知识服务,从技术、架构、业务、管理、思想等多方面来给正在路上的技术人提供一些参考,解答一些疑惑。现将听取的部分大牛的讲话内容记录下来,以此来总结反思自己。
从书上学·在事中练·与高人聊!心力!
极客邦访谈100位牛人,通过直播方式为程序员提供知识服务,从技术、架构、业务、管理、思想等多方面来给正在路上的技术人提供一些参考,解答一些疑惑。现将听取的部分大牛的讲话内容记录下来,以此来总结反思自己。
作为ROLAP引擎的SparkSQL具备丰富的SQL算子,比如关联、聚合、分组、窗口函数以及内置的各种函数、hint等等,在功能层面较好地满足了业务分析场景的需要。作为平台工具的开发者,在提供好用、稳定的工具的同时,更要掌握一定的SQL使用方式,来加深各个算子在实际场景的应用效果。故开此文,长期记录使用SQL进行经典OLAP分析的场景或者是一些奇淫技巧。
Apache Kylin是Hadoop大数据平台上的一个开源MOLAP引擎。它采用多维立方体预计算技术,可以将大数据的SQL查询速度提升到亚秒级别。在2015年成为Apache的顶级项目,在2016年核心团队创立了Kyligence公司。
Spark(Spark SQL)在离线计算场景应用广泛,为了保证Spark应用更好地满足业务场景需求,同时能够在线上稳定地运行,我们需要关注Spark的调优工作。首先,需要了解Spark对外的接口并如何高效地使用;其次要搞清楚内部的运行机制以及参数配置体系;最后是要能够深入分析spark的日志信息。进一步来讲,对于Spark的深度使用者,需要关注社区各个版本的迭代、bug修复以及性能优化的情况,才能更好地打开思路,提高解决问题的效率。主要途径有:spark的release-note、databricks官方博客、源码。
为了方便Spark相关性能问题的排查,本文记录了日常Spark使用过程中遇到的问题和解决思路,用于积累过程中进行复盘总结,强化Spark的深入理解和实战经验。
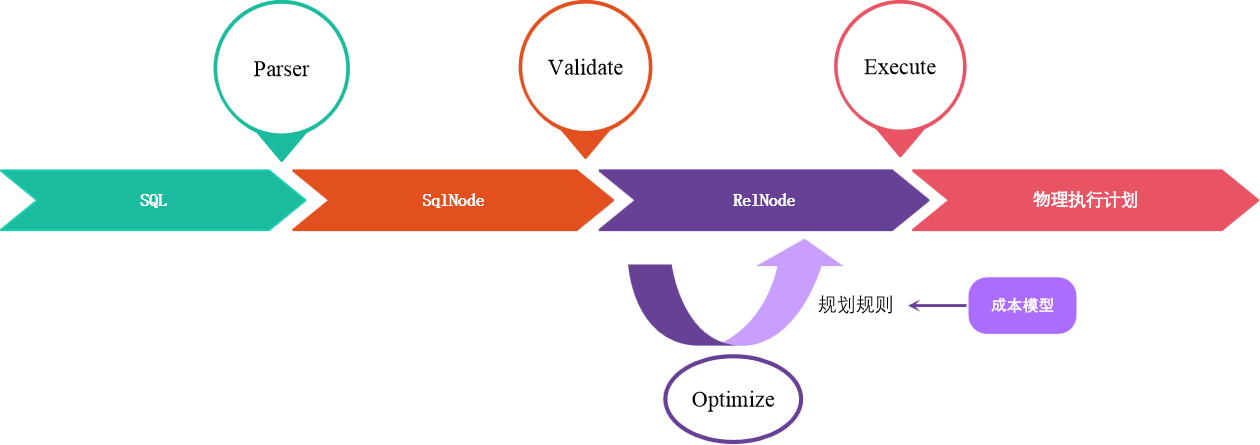
相关概述与特性,可以查看之前的文章《Calcite原理和经验总结》。
如果近几年从业于软件工程,特别是服务器端和后端系统开发,那么您很有可能已经被大量关于数据存储和处理的时髦词汇轰炸过了: NoSQL!大数据!Web-Scale!分片!最终一致性!ACID! CAP定理!云服务!MapReduce!实时! 在最近十年中,我们看到了很多有趣的进展,关于数据库,分布式系统,以及在此基础上构建应用程序的方式。
本文首先介绍什么是分布式系统,跟集群有什么区别。其次,引入事务ACID的概念以及在单机过渡到分布式后产生哪些问题和解决方式,包括CAP/BASE理论、2PC、3PC等。最后,介绍分布式事务中协调者的共识问题,从而引入Paxos、Raft分布式一致性协议算法。