数据库之行列存储简介
前言
数据库之所以有行存和列存之分,主要是为了满足不同的使用场景。我们常见的Oracle、MySQL等主流关系型数据库都是以行存为主,适合OLTP的应用,涉及事务处理、增删改查等操作。随着大数据的发展,新兴的Vertica、Greenplum、MonetDB、C-Store等数据库支持列式存储,适合OLAP的应用,涉及海量数据的分析操作。甚至业界一些数据库为了同时支持OLTP和OLAP的能力,采用行列混合存储的模式,来兼容这两种应用场景。因此,数据库采用不同的数据存储布局,决定了它本身对外支持的特性,用户据此并结合业务场景来选择合适的数据库产品。下面,本文将主要针对行列存储的概念、组织形式、优缺点进行简要介绍。
基本概念
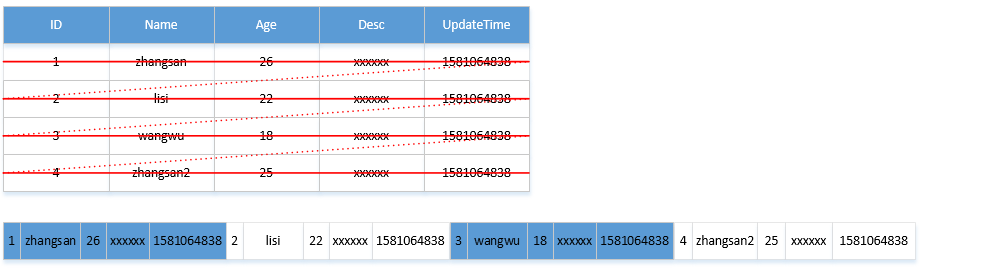
在基于行式存储的(row-based storage)数据库中,数据是按照行的逻辑存储单元进行存储的,一个整行的数据在存储介质中以连续形式存在。如下图所示:
在基于列式存储的(column-based storage)数据库中,数据是按照列的逻辑存储单元进行存储的,一个整列的数据在存储介质中以连续形式存在。如下图所示:

以上描述的是行列存储的逻辑结构,具体物理层面的数据布局,要看各数据库支持行或列物理存储的具体实现。
优缺点分析
行式存储可以将一行数据一次性写入,保证数据的完整性。在读取过程中,根据条件进行精确查询时,可以一次性读取整行数据返回。但针对按列统计分析时,如果涉及的数据量大,读取整行时会存在大量冗余列,占用系统资源高,影响读取性能。
列式存储由于是按照列来存储,每列都有各自的数据类型,同一个类型的数据放在一起存储,方便做对应的编码压缩(比如行程编码、字典编码),极大地节省存储空间和传输带宽,同时也降低了按列分析的IO操作。但是,按列拆开存储,数据的完整性和写入效率也会不如行式存储,同时针对精确查询并且返回大部分列时也会产生大量IO。
适用场景
根据行存的特性,比较适用于OLTP的应用场景,比如小数据量的事务型增删改查操作。然而,为了应对海量数据的存储和计算,传统的OLTP数据库并不能满足。因此,列存的特性适用于海量日志型数据的分析查询,可以用一张成百上千个列的宽表来存储分析这些数据,各列独自存储,也提高了并发读取的性能。
总结
以上介绍了行式存储和列式存储的基本概念、组织方式、各自的优缺点以及应用场景。可以看出,列存相对于行存,在存储压缩、按列分析、降低IO等方面存在优势,但在精确查询返回大部分列时存在不足。因此,在一些分析型数据库存储引擎中引入了行列混合存储的概念,来兼顾OLAP式查询和精确查询的两种场景,这个后续再做介绍。
参考资料
- Abadi D J , Madden S R , Hachem N . Column-stores vs. row-stores: How different are they really?[C]// Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008. ACM, 2008.
- https://www.the-paper-trail.org/post/2013-01-30-columnar-storage/
- C. Zhan, M. Su, C. Wei, X. Peng, L. Lin, S. Wang, Z. Chen, F. Li, Y. Pan, F. Zheng, C. Chai, AnalyticDB: Real-time OLAP Database System at Alibaba Cloud, VLDB 2019.