2020-DTCC-参会分享

本届大会的主题围绕“架构革新、高效可控”为主题,历时三天,涵盖内容包括数据库底层内核代码开发,数据库的架构设计,数据库技术云平台实践以及上层AI和大数据应用。
数据库新趋势
大会主会场分两天展开,内容起到了提纲挈领的作用。
来自达梦数据库副总经理冯源谈古说今,介绍了数据库从早期到现在的发展,都是围绕实际需求来的。其中,谈到了分布式数据库概念在当时就已经提出来并研究,为啥没有发展起来?主要是当时的通信方式还是以电话线作为连接,网络通信成本很高。后来硬件的发展非常快速,使得数据库机器在scale up层面就可以提升数据库的性能。到了如今,随着数据量的激增,单机数据库的局限性越来越明显,比如谷歌全球性服务、异地多活等需求的出现,使得分布式数据库技术再次发展起来。
总结来说,数据库技术发展遵循了“需求第一性”的原则,要有走向业务的意识。最后,冯总还提到了当下数据库产品处于百花齐放的势头。来自贝壳找房技术总监侯圣文,作为主持人总结到当下我们要把握住数据库技术发展的变与不变的核心问题。我的理解在这么多数据库产品当中,以业务需求或解决业务问题为出发点,才能选择到合适的数据库产品。
从当下业务场景来看,比如电商大促、国际化云服务等,对数据库资源的弹性扩缩容、夸AZ/Region,甚至全球的服务能力提出了强烈的诉求。伴随着云计算技术的发展,提供了资源池化,计算、存储、网络等资源解耦的能力,促使数据库上云或云原生数据库的发展走上舞台。来自阿里集团副总裁、阿里云智能数据库事业部总负责人李飞飞(飞刀)带来他的分享主题“企业级云原生分布式数据库与数据仓库系统:挑战与机遇”。会上,他给出了在云计算加速数据库系统演进的整个业界趋势,这里列一下在不同阶段的代表性数据库产品:
- 1980-1990商业起步阶段:Oracle、IBM DB2、Sybase、SQL Server、Infomix;
- 1990-2000开源阶段:Postgres、MySQL;
- 1990-2000分析阶段:Teradata、Sybase IQ、Greenplum;
- 2000-2010异构NoSQL:Hadoop、HBase、SAP Hana、MongoDB、Redis;
- 2010-2019云原生、一体化分布式、多模、HTAP:AWS Aurora、Redshift、Azure SQL Database、Google Spanner、Snowflake
根据上诉不同阶段的数据库产品,从产品技术以及处理问题维度可以归纳为如下几部分:
- 结构化数据在线处理:RDBMS[SQL+OLTP];
- 海量数据计算与分析:数仓Data warehouse、Data Cube[ETL+OLAP];
- 异构数据类型:结构化、时序、时空、图数据、向量数据、文本数据;
- 形态变化:关系型数据库、NoSQL/NewSQL数据库、云原生分布式/软硬一体化、多模/HTAP。
由此可见,当下数据库新技术趋势就是以云原生、分布式为基准,具备计算分析一体化(减少数据移动)、存储计算分离(资源池化、解耦)的能力。另外,飞飞老师从阿里云产品角度阐述了云原生关系数据库PolarDB、云原生分布式数据库PolarDB-X、云原生数仓AnalyticDB以及云原生数据湖DLA(Data Lake Analytics)。这里,我想分享一下令我影响比较深刻或者算是解答我心中疑惑的点:
存算分离后,降低了计算本地性,是如何规避性能损耗的?
存算分离带来的好处就是计算实例可以按需扩容,在PolarDB或ADB中多个存储实例间采用了Raft同步Redo Log,对计算实例提供基于用户态IO+NVM+RDMA的存储高速访问能力。而存储实例本身使用OSS(存冷数据)作为共享存储,同时加入ESSD(或者类似的加速卡来缓存热数据),通过高速网络与计算实例交互。上述各种黑科技的加持,可见大厂为了让公有云提供给用户更好的产品和服务投入很多。
数据仓库和数据湖的区别?
简单理解的话,数仓类似现实生活中的物品仓库,需要按照一定类目来摆放物品,就是说数据仓库中的数据是经过加工提炼之后的数据,并且按照一定的组织方式来存放。而数据湖中的数据是杂乱无章的,这些数据都有各自的组织方式,但是它们都有明确的元数据信息来描述它们的位置和模式等相关信息,能方便我们通过数据湖内置的计算引擎(比如presto、spark等)进行按需获取加工处理再次以新的数据和模式存储在湖中,从而形成一个一体化的数据分析系统。
云原生在数仓和数据湖中起动什么作用?
当下K8s已经基本成为云操作系统的标准,云原生能力通过K8s来提供FPGA、GPU、CPU、内存和网络的虚拟化资源。因此,在云原生能力的加持下,使得数据库具备弹性扩展能力。不过,这对数据库具备存算分离的能力提出了要求。
同样来自华为云数据库技术专家彭立勋,提出了GaussDB在云原生下存算分离的理念。基于华为多年的存储和网络的优势,提供了分布式一致性可扩展存储能力,在存储层提供元数据管理以及一致性的视图访问能力。而计算层的SQL和索引层,都有各自不同的生态、事务、存储管理方式,比如B-Tree\LSM Tree\KV等。最终,达到了计算层无状态、存储深度融合提供强一致性。
再说说来自阿里云智能数据库产品管理与运营部总经理叶正盛“数据库2025”的分享,他提到Gartner已经将数据库OLTP、OLAP以及大数据能力整合到一起来评估数据库能力。结合百度云数仓和AI平台总架构师马如悦的“百度数据平台发展趋势”的分享,我的理解是作为一个DBMS,重点是要做好数据的管理,用户关心的是数据,至于管理数据的手段,比如传统数据库、大数据技术、云原生、ACID、智能化、软硬件融合等能力,甚至在此之上构建的平台、中台能力,已然成为一个工具或系统需要逐步具备的,只有管理好了数据,才能提供给用户更好的数据服务。最后,叶正盛老师提出对2025数据库的展望,就是迎接数据时代,全面普及云原生数据库以及数据仓库,数据库自动驾驶,国产数据库全面崛起。
个人感觉整个基调就是当前数据库技术的发展,云原生是个大的趋势,同时在技术发展过程中要贴近业务的需求,去理解业务,赋能业务,发挥数据库技术在数字化转型中的重要作用。
数据库上云之路
上面抛出了那么多概念,那各个厂商的上云之路走得又如何呢?
首先在上云方面,在分会场“大数据架构设计”中,来自金山云大数据平台基础架构技术负责人关海南带来了“金山云大数据架构与容器化实践”的分享,传达了上云之路的现状。比如,针对无状态的业务应用,在k8s上运行基本问题不大。而针对有状态的分布式应用,在k8s上存在一些坑。比如zk在k8s网络如果发生抖动时会导致死锁,在kafka中会导致主从不一致性的问题。因此,针对一些有状态的组件以及核心业务目前还在k8s之外。另外,金山云在spark on k8s上也进行了一些尝试,采用社区spark2.x的版本并进行了一些改动。事实上,spark on k8s在社区还支持得不怎么好,主流还是spark on yarn方式。spark on yarn, yarn on k8s的方式其实显得并不那么云原生。来自HashData的CEO简丽荣也提到,在大数据时代是HDFS+YARN,而在云原生时代应该是k8s+oss。
与此同时,在分会场“云原生数据库开发与实践”中,来自京东云专家架构、云数据库技术负责人张成远在“云数据库建设实践”也提出了自己的一些想法。从传统基础软件,到基础软件上云,到云原生模式,意味着不是软件部署在k8s上了就表示具备云原生了,云原生在更大范围内应该是基于从传统IDC到云之后变化,在此基础上构建出的云原生应用,具备了serverless化,到最终数据库价值就应该在于数据了而不是数据库本身,不用考虑以往存储不够怎么办,并发能力不够怎么等之类的问题,而是追求如何发挥数据的价值。而在当下,做得比较云原生的典范,并且在大会中多次被老师提到的,应该就是snowflake了。
来自沃趣科技技术中心负责人魏兴华,在“构建新一代数据库平台基础设施”中谈到,他们已经具备管理上万节点的容器平台,对k8s的未来非常看好。他做了一个比较形象的类比,k8s中推出了operator组件能力,相当于传统linux机器之上应用rpm包,同时operator还可以内置各种自检、恢复、备份等运维人员的大量经验,从而实现自动化处理。比如,tidb-operator就可以极大方便在k8s上部署、运维tidb。他强调,云原生就是一切要以应用为中心的思想,支撑业务应用的快速迭代和创新,比如负载均衡、限流熔断、弹性伸缩、资源调度等等,都交给云来解决就可以了。
数据[库]架构设计
另外,想分享的点就是“技术演进≠产品消亡”。企业要以”数据“为中心,不仅仅要在数据库本身投入精力,更应该做好数据架构的设计。
从大会多个议题上可以看出,mysql、pg等关系数据库仍然是众多讨论的话题。比如,基于MySQL的星环KunDB、工行MySQL治理实践、MySQL容器化实践、MySQL中间件思考与实践、MySQL高可用之路,就连快手春晚红包支撑百万TPS的TP数据库也是MySQL。为了解决大数据量下关系数据库的正常交易,基于关系型数据的分库分表、垂直水平扩容、分布式事、多副本、高可用的能力需求依旧存在。另外,数据库中间件Apache ShardingSphere已于2020年4月16日成为 Apache 软件基金会的顶级项目,也可见一斑。
很多厂商为了追求HTAP的能力,从架构、产品本身做了很多事情。我的理解是主要分为以下三类:
- 一种是平台层面打造TP+AP的整合能力;
- 一种是数据库本身的TP和AP能力;
- 一种是满足特定业务场景的多个组件整合、业务特性固化下沉能力。
下面列举几个参会中一些厂家的数据架构:
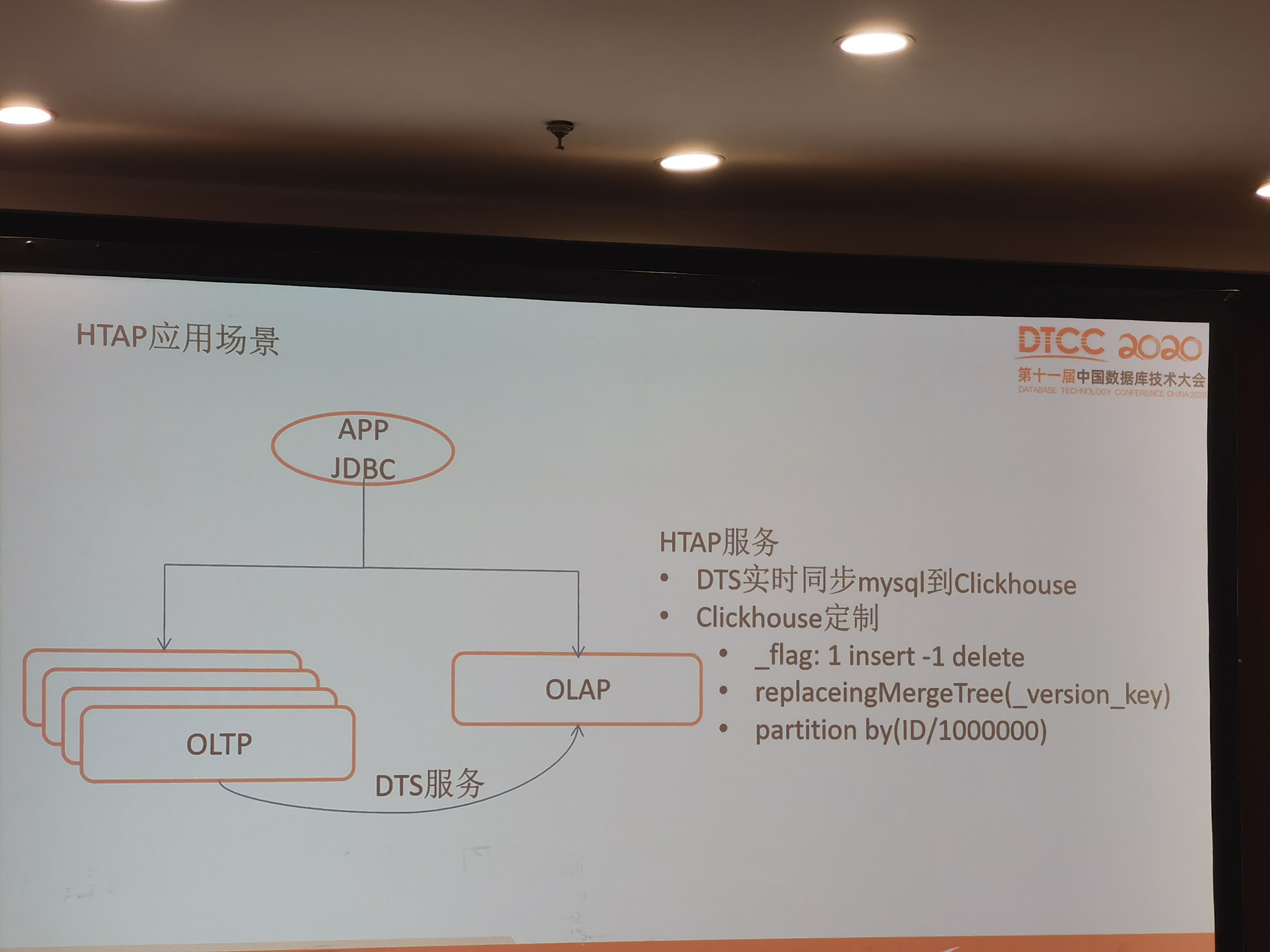
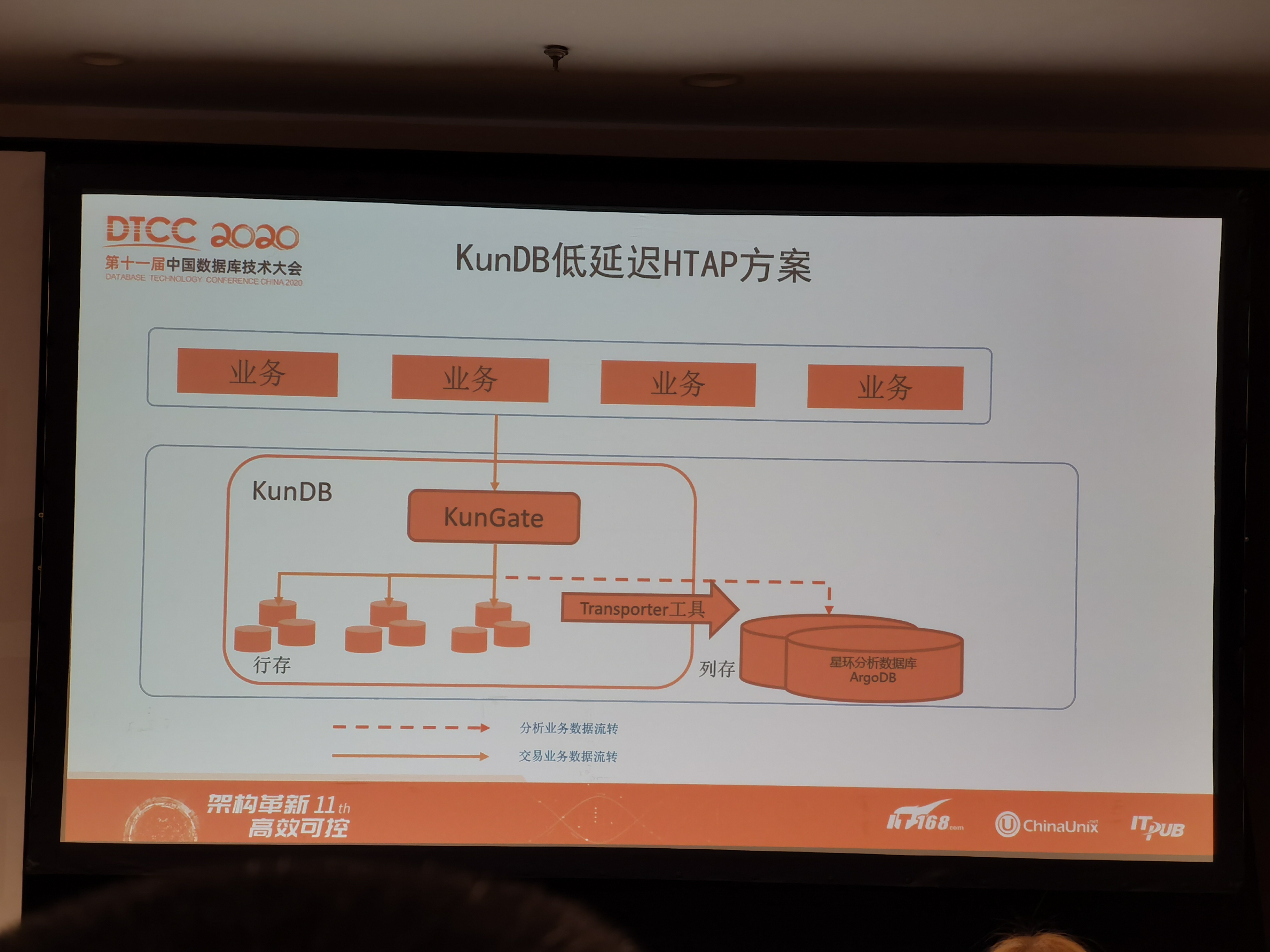
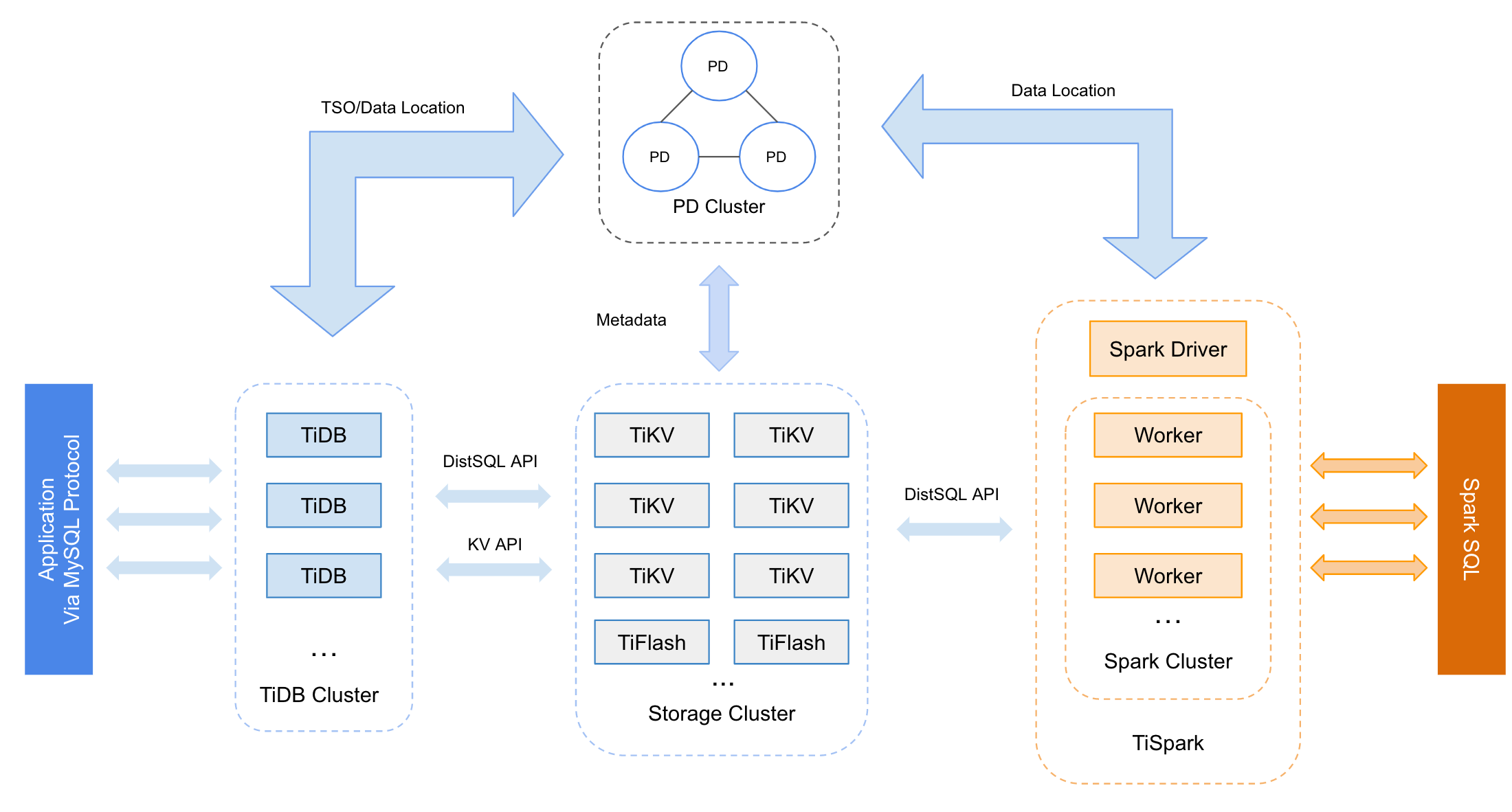
图二、三采用了DTS数据同步工具,将TP中数据同步到AP库中,针对DTS的能力提出了很高的要求,比如数据一致性问题、schema变化等等,这要根据业务的使用场景来定。图四提出了一个比较新颖的方式,将TP中的行存结构,在多副本同步(raft group)的过程中,形成一份列存的副本,用于AP场景的分析。
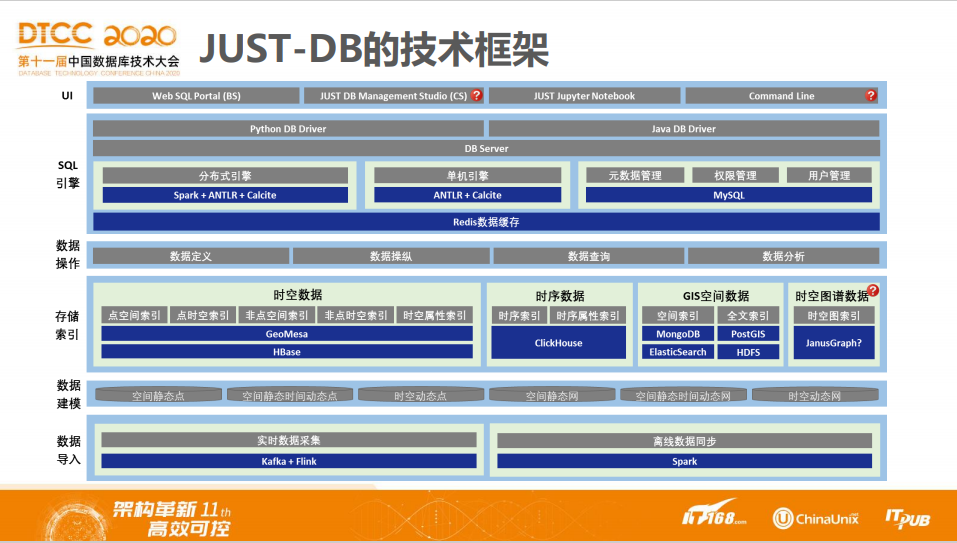
图五,展示了实现时空数据的查询分析能力的技术组件整合能力和关键技术(比如轨迹数据存储)的突破能力。
总结与收获
通过参与本次2020年度DTCC大会,发现当前数据库、数据仓库、数据湖技术的发展,都在强调对外的生态,比如兼容客户端通信协议,降低迁移的门槛。同时使用的开源软件技术栈也相对比较集中,比如mysql、postgresql、redis、hbase、mongodb、kafka、flink、spark、orc/parquet、presto、clickhouse、oss、k8s等,关注的技术难点比如分布式事务、raft/paxos协议、DTS同步性能、异地多活、有状态应用容器化的坑、大规模集群实践等。
那么除了头部厂商闭源自研能力外,以开源系为基石的很多厂商在数据库产品竞争力也是不容小觑的。能够满足企业级的业务场景,打造适合自己的数据库产品,各家都有自己的产品创新、技术整合能力,甚至会回馈到社区,发挥出更大的价值。关键是要有场景的验证与沉淀,才能孵化并打磨出一款好的产品,优美的技术架构,从而给客户一个更好的数据赋能业务的一整套解决方案。
这也进一步验证了数据库技术发展过程中的变与不变的辩证关系。作为该领域的从业者,要牢牢把握不变的地方,来从容面对日益变化的数据库产品迭代和业务需求。
以上就是本次参会的一些分享,由于个人能力有限,以上内容表述可能会有不当,欢迎交流指正。
扩展阅读
- 黄东旭, PingCAP CTO, 云原生数据库设计新思路.
- 李瑞远,博士,京东城市时空数据组负责人,京东城市时空数据引擎 JUST.